你不知道的 Node:核心功能快速介紹
這篇文章的靈感來自 Kyle Simpson 的系列書籍,You Don't Know JavaScript .它們是 JavaScript 基礎知識的良好開端。 Node 主要是 JavaScript,除了我將在本文中強調的一些差異。代碼在 You Don't Know Node code 下的 GitHub 倉庫 文件夾。
為什麼要關心 Node? Node 是 JavaScript,而 JavaScript 幾乎無處不在!如果更多的開發人員掌握 Node,世界會變得更美好怎麼辦?更好的應用等於更好的生活!
這是主觀上最有趣的核心功能的廚房水槽。本文的主要內容是:
- 事件循環:重溫實現非阻塞 I/O 的核心概念
- 全局和流程:如何訪問更多信息
- 事件發射器:基於事件的模式中的速成課程
- 流和緩衝區:處理數據的有效方式
- 集群:像專業人士一樣分叉進程
- 處理異步錯誤:AsyncWrap、Domain 和 uncaughtException
- C++ 插件:貢獻核心並編寫您自己的 C++ 插件
事件循環
我們可以從 Node 核心的事件循環開始。
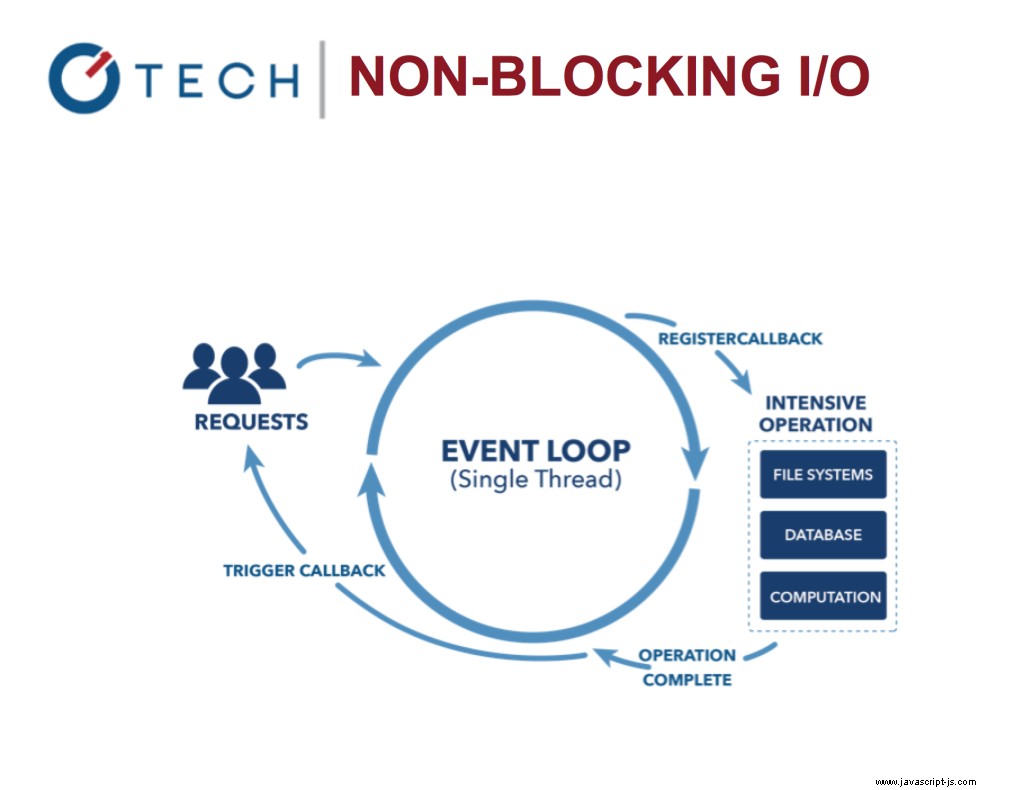
Node.js 非阻塞 I/O
它允許在處理 IO 調用時處理其他任務。想想 Nginx 與 Apache。它讓 Node 變得非常快速和高效,因為阻塞 I/O 很昂貴!
看看這個延遲 println 的基本示例 Java中的函數:
System.out.println("Step: 1");
System.out.println("Step: 2");
Thread.sleep(1000);
System.out.println("Step: 3");
它與這個 Node 代碼相當(但不是真的):
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
}, 1000)
console.log('Step: 2')
不過不完全一樣。您需要開始以異步方式思考。 Node腳本的輸出是1、2、3,但是如果我們在“Step 2”之後有更多的語句,它們會在setTimeout的回調之前執行 .看看這個片段:
console.log('Step: 1')
setTimeout(function () {
console.log('Step: 3')
console.log('Step 5')
}, 1000);
console.log('Step: 2')
console.log('Step 4')
它產生 1、2、4、3、5。那是因為 setTimeout 將它的回調放在了事件循環的未來循環中。
將事件循環想像成像 for 這樣的旋轉循環 或 while 環形。僅當現在或將來沒有要執行的內容時才會停止。
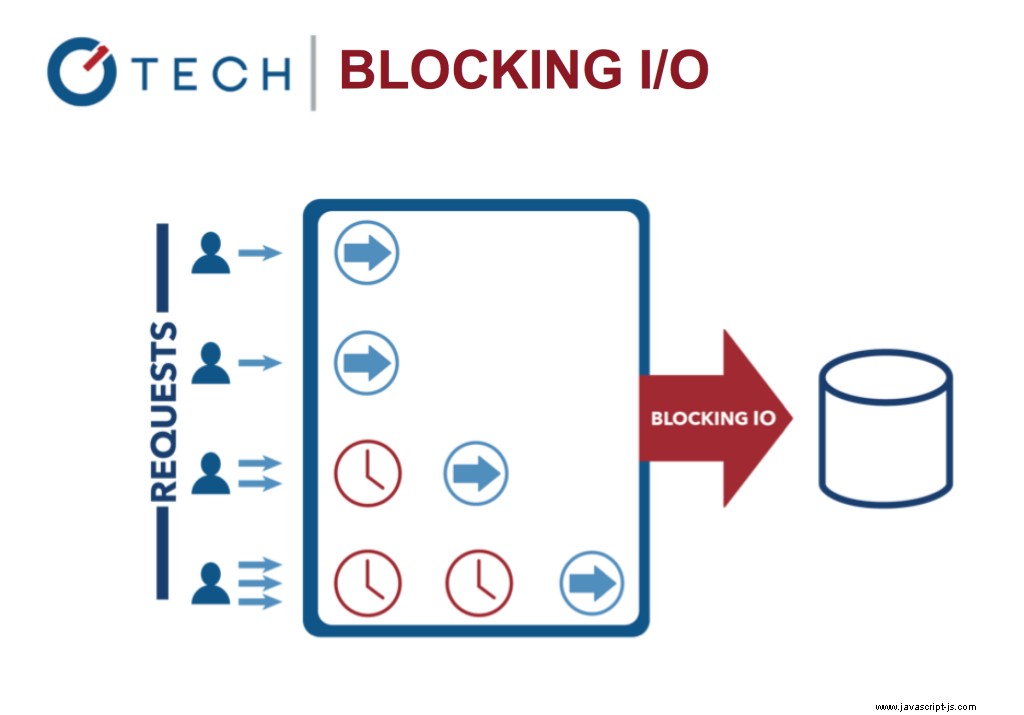
阻塞 I/O:多線程 Java
事件循環使系統更有效,因為現在您可以在等待昂貴的輸入/輸出任務完成時做更多的事情。
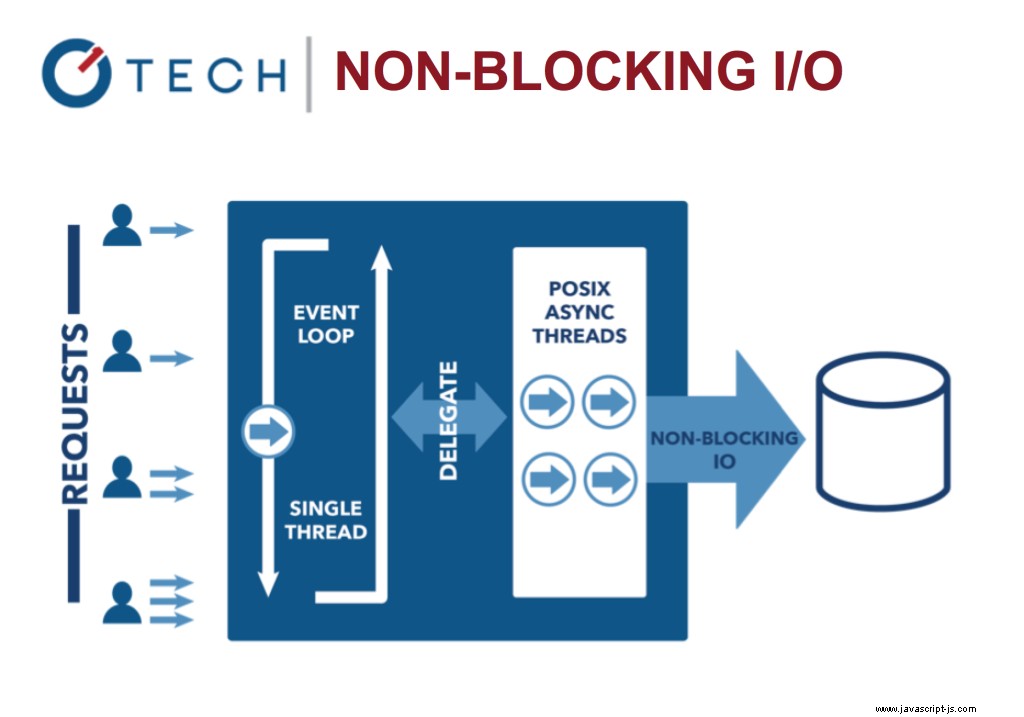
非阻塞 I/O:Node.js
這與當今使用 OS 線程的更常見的並發模型形成對比。基於線程的網絡效率相對較低且非常難以使用。此外,Node 用戶無需擔心進程死鎖——沒有鎖。
附註:仍然可以在 Node.js 中編寫阻塞代碼。 ?考慮一下這個簡單但阻塞的 Node.js 代碼:
console.log('Step: 1')
var start = Date.now()
for (var i = 1; i<1000000000; i++) {
// This will take 100-1000ms depending on your machine
}
var end = Date.now()
console.log('Step: 2')
console.log(end-start)
當然,大多數時候,我們的代碼中沒有空循環。在使用其他人的模塊時,發現同步並因此阻塞代碼可能會更難。例如,核心 fs (文件系統)模塊自帶兩套方法。每對執行相同的功能,但方式不同。有阻塞fs 包含 Sync 字樣的 Node.js 方法 以他們的名義:
[旁注]
閱讀博客文章很好,但觀看視頻課程更好,因為它們更具吸引力。
許多開發人員抱怨 Node.js 上缺乏負擔得起的高質量視頻材料。觀看 YouTube 視頻會讓人分心,花 500 美元購買 Node 視頻課程很瘋狂!
去看看 Node University,它有關於 Node 的免費視頻課程:node.university。
[旁注結束]
var fs = require('fs')
var contents = fs.readFileSync('accounts.txt','utf8')
console.log(contents)
console.log('Hello Ruby\n')
var contents = fs.readFileSync('ips.txt','utf8')
console.log(contents)
console.log('Hello Node!')
即使對於 Node/JavaScript 的新手來說,結果也是非常可預測的:
data1->Hello Ruby->data2->Hello NODE!
當我們切換到異步方法時,情況會發生變化。這是非阻塞 Node.js 代碼:
var fs = require('fs');
var contents = fs.readFile('accounts.txt','utf8', function(err,contents){
console.log(contents);
});
console.log('Hello Python\n');
var contents = fs.readFile('ips.txt','utf8', function(err,contents){
console.log(contents);
});
console.log("Hello Node!");
它最後打印內容,因為它們需要一些時間來執行,它們在回調中。當文件讀取結束時,事件循環將到達它們:
Hello Python->Hello Node->data1->data2
所以事件循環和非阻塞 I/O 非常強大,但是你需要異步編碼,這不是我們大多數人在學校學習編碼的方式。
全球
從瀏覽器 JavaScript 或其他編程語言切換到 Node.js 時,會出現以下問題:
- 在哪裡存儲密碼?
- 如何創建全局變量(無
window在節點中)? - 如何訪問 CLI 輸入、操作系統、平台、內存使用情況、版本等?
有一個全局對象。它具有某些特性。其中一些如下:
global.process:進程、系統、環境信息(可以訪問CLI輸入、帶密碼的環境變量、內存等)global.__filename:該語句所在的當前運行腳本的文件名和路徑global.__dirname:當前運行腳本的絕對路徑global.module:導出代碼的對象,使這個文件成為一個模塊global.require():導入模塊、JSON 文件和文件夾的方法
然後,我們得到了通常的嫌疑人,來自瀏覽器 JavaScript 的方法:
global.console()global.setInterval()global.setTimeout()
每個全局屬性都可以使用大寫名稱 GLOBAL 訪問 或者根本沒有命名空間,例如,process 而不是 global.process .
流程
Process 對像有很多信息,因此它值得擁有自己的部分。我將僅列出一些屬性:
process.pid:此 Node 實例的進程 IDprocess.versions:各種版本的Node、V8等組件process.arch:系統架構process.argv:CLI 參數process.env:環境變量
部分方法如下:
process.uptime():獲得正常運行時間process.memoryUsage():獲取內存使用情況process.cwd():獲取當前工作目錄。不要與__dirname混淆 這不取決於進程的啟動位置。process.exit():退出當前進程。您可以傳遞 0 或 1 之類的代碼。process.on():附加一個事件監聽器,例如,`on('uncaughtException')
棘手的問題:誰喜歡和理解回調? ?
有些人太喜歡回調,所以他們創建了 http://callbackhell.com。如果你還不熟悉這個術語,這裡有一個例子:
fs.readdir(source, function (err, files) {
if (err) {
console.log('Error finding files: ' + err)
} else {
files.forEach(function (filename, fileIndex) {
console.log(filename)
gm(source + filename).size(function (err, values) {
if (err) {
console.log('Error identifying file size: ' + err)
} else {
console.log(filename + ' : ' + values)
aspect = (values.width / values.height)
widths.forEach(function (width, widthIndex) {
height = Math.round(width / aspect)
console.log('resizing ' + filename + 'to ' + height + 'x' + height)
this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) {
if (err) console.log('Error writing file: ' + err)
})
}.bind(this))
}
})
})
}
})
回調地獄很難閱讀,而且容易出錯。除了在開發上不太可擴展的回調,我們如何模塊化和組織異步代碼?
事件發射器
為了幫助回調地獄或末日金字塔,有事件發射器。它們允許使用事件來實現您的異步代碼。
簡而言之,事件發射器是觸發任何人都可以收聽的事件的東西。在 node.js 中,一個事件可以描述為一個帶有相應回調的字符串。
事件發射器有以下用途:
- Node 中的事件處理使用觀察者模式
- 事件或主題會跟踪與其關聯的所有功能
- 這些關聯的函數,稱為觀察者,在給定事件觸發時執行
要使用事件發射器,請導入模塊並實例化對象:
var events = require('events')
var emitter = new events.EventEmitter()
之後,您可以附加事件偵聽器並觸發/發出事件:
emitter.on('knock', function() {
console.log('Who\'s there?')
})
emitter.on('knock', function() {
console.log('Go away!')
})
emitter.emit('knock')
讓我們用 EventEmitter 做一些更有用的東西 通過繼承它。想像一下,您的任務是實現一個類來執行每月、每周和每天的電子郵件工作。該類需要足夠靈活,以便開發人員自定義最終輸出。換句話說,無論誰使用這個類,都需要能夠在工作結束時放置一些自定義邏輯。
下圖解釋了我們從 events 模塊繼承來創建 Job 然後使用 done 事件監聽器自定義Job的行為 類:

Node.js 事件發射器:觀察者模式
類 Job 將保留其屬性,但也會獲取事件。我們只需要觸發 done 當過程結束時:
// job.js
var util = require('util')
var Job = function Job() {
var job = this
// ...
job.process = function() {
// ...
job.emit('done', { completedOn: new Date() })
}
}
util.inherits(Job, require('events').EventEmitter)
module.exports = Job
現在,我們的目標是自定義 Job 的行為 在任務結束時。因為它發出 done ,我們可以附加一個事件監聽器:
// weekly.js
var Job = require('./job.js')
var job = new Job()
job.on('done', function(details){
console.log('Job was completed at', details.completedOn)
job.removeAllListeners()
})
job.process()
發射器還有更多功能:
emitter.listeners(eventName):列出給定事件的所有事件監聽器emitter.once(eventName, listener):附加一個只觸發一次的事件監聽器。emitter.removeListener(eventName, listener):移除事件監聽器。
事件模式在整個 Node 中使用,尤其是在其核心模塊中。出於這個原因,掌握事件將為您的時間帶來巨大的收益。
流
在 Node.js 中處理大數據時存在一些問題。速度可能很慢,緩衝區限制約為 1Gb。另外,如果資源是連續的,你將如何工作,in 從來沒有被設計為結束?要克服這些問題,請使用流。
節點流是數據連續分塊的抽象。換句話說,無需等待整個資源加載完畢。看看下圖顯示標準緩衝方法:

Node.js 緩衝方法
在開始處理和/或輸出之前,我們必須等待整個緩衝區加載完畢。現在,將其與下一個描述流的圖表進行對比。在其中,我們可以從第一個塊開始處理數據和/或立即輸出:

Node.js 流方法
Node 中有四種類型的 Stream:
- 可讀性:您可以從中閱讀
- 可寫:您可以給他們寫信
- 雙工:可以讀寫
- 轉換:您可以使用它們來轉換數據
流在 Node 中幾乎無處不在。最常用的流實現有:
- HTTP 請求和響應
- 標準輸入/輸出
- 文件讀寫
Streams 繼承自 Event Emitter 對像以提供觀察者模式,即事件。還記得他們嗎?我們可以用它來實現流。
可讀流示例
可讀流的示例是 process.stdin 這是一個標準輸入流。它包含進入應用程序的數據。輸入通常來自用於啟動進程的鍵盤。
從 stdin 讀取數據 , 使用 data 和 end 事件。 data 事件的回調將有 chunk 作為它的論據:
process.stdin.resume()
process.stdin.setEncoding('utf8')
process.stdin.on('data', function (chunk) {
console.log('chunk: ', chunk)
})
process.stdin.on('end', function () {
console.log('--- END ---')
})
所以 chunk 然後輸入到程序中。根據輸入的大小,此事件可以觸發多次。一個 end event 是輸入流結束的必要信號。
注意:stdin 默認是暫停的,必須恢復才能讀取數據。
可讀流也有 read() 同步工作的接口。它返回 chunk 或 null 當流結束時。我們可以使用這種行為並將 null !== (chunk = readable.read()) 進入 while 條件:
var readable = getReadableStreamSomehow()
readable.on('readable', () => {
var chunk
while (null !== (chunk = readable.read())) {
console.log('got %d bytes of data', chunk.length)
}
})
理想情況下,我們希望盡可能在 Node 中編寫異步代碼,以避免阻塞線程。但是,數據塊很小,所以我們不用擔心同步 readable.read() 阻塞線程 .
可寫流示例
一個可寫流的例子是 process.stdout .標準輸出流包含從應用程序輸出的數據。開發人員可以使用 write 寫入流 操作。
process.stdout.write('A simple message\n')
寫入標準輸出的數據在命令行上可見,就像我們使用 console.log() 時一樣 .
管道
Node 為開發人員提供了事件的替代方案。我們可以使用 pipe() 方法。本例從文件中讀取,用 GZip 壓縮,然後將壓縮後的數據寫入文件:
var r = fs.createReadStream('file.txt')
var z = zlib.createGzip()
var w = fs.createWriteStream('file.txt.gz')
r.pipe(z).pipe(w)
Readable.pipe() 接受一個可寫流並返回目的地,因此我們可以鏈接 pipe() 方法一個接一個。
因此,當您使用流時,您可以在事件和管道之間進行選擇。
HTTP 流
我們大多數人都使用 Node 來構建傳統的(想想服務器)或 RESTful APi(想想客戶端)的 Web 應用程序。那麼 HTTP 請求呢?我們可以流式傳輸嗎?答案是響亮的是的 .
請求和響應是可讀和可寫的流,它們繼承自事件發射器。我們可以附加一個 data 事件監聽器。在它的回調中,我們將收到 chunk ,我們可以立即對其進行轉換,而無需等待整個響應。在這個例子中,我連接了 body 並在 end 的回調中解析它 事件:
const http = require('http')
var server = http.createServer( (req, res) => {
var body = ''
req.setEncoding('utf8')
req.on('data', (chunk) => {
body += chunk
})
req.on('end', () => {
var data = JSON.parse(body)
res.write(typeof data)
res.end()
})
})
server.listen(1337)
注意:()=>{} const 是粗箭頭函數的 ES6 語法 是一個新的運算符。如果您還不熟悉 ES6/ES2015 功能和語法,請參閱文章
每個忙碌的 JavaScript 開發人員必須知道的 10 大 ES6 功能 .
現在讓我們使用 Express.js 讓我們的服務器更接近現實生活中的示例。在下一個示例中,我有一個巨大的圖像 (~8Mb) 和兩組 Express 路由:/stream 和 /non-stream .
server-stream.js:
app.get('/non-stream', function(req, res) {
var file = fs.readFile(largeImagePath, function(error, data){
res.end(data)
})
})
app.get('/stream', function(req, res) {
var stream = fs.createReadStream(largeImagePath)
stream.pipe(res)
})
我還有一個在 /stream2 中帶有事件的替代實現 /non-stream2 中的同步實現 .它們在流式傳輸或非流式傳輸方面做同樣的事情,但語法和風格不同。這種情況下的同步方法性能更高,因為我們只發送一個請求,而不是並發請求。
要啟動示例,請在終端中運行:
$ node server-stream
然後在 Chrome 中打開 http://localhost:3000/stream 和 http://localhost:3000/non-stream。 DevTools 中的 Network 選項卡將顯示標題。比較 X-Response-Time .就我而言,/stream 的數量級要低 和 /stream2 :300ms vs. 3-5s。
您的結果會有所不同,但想法是使用流,用戶/客戶端將更早開始獲取數據。節點流真的很強大!有一些很好的直播資源可以讓您掌握它們並成為您團隊中的首選直播專家。
[Stream Handbook](https://github.com/substack/stream-handbook] 和可以使用 npm 安裝的 stream-adventure:
$ sudo npm install -g stream-adventure
$ stream-adventure
緩衝區
我們可以為二進制數據使用什麼數據類型?如果你還記得,瀏覽器 JavaScript 沒有二進制數據類型,但 Node 有。它被稱為緩衝區。它是一個全局對象,所以我們不需要將它作為模塊導入。
要創建二進制數據類型,請使用以下語句之一:
Buffer.alloc(size)Buffer.from(array)Buffer.from(buffer)Buffer.from(str[, encoding])
官方的 Buffer 文檔列出了所有的方法和編碼。最流行的編碼是 utf8 .
一個典型的緩衝區看起來像亂碼,所以我們必須將其轉換為帶有 toString() 的字符串 具有人類可讀的格式。 for 循環將創建一個帶有字母的緩衝區:
let buf = Buffer.alloc(26)
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97 // 97 is ASCII a
}
如果我們不將其轉換為字符串,緩衝區將看起來像一個數字數組:
console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
我們可以使用 toString 將緩衝區轉換為字符串。
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz
buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz
如果我們只需要一個子字符串,則該方法需要一個起始編號和結束位置:
buf.toString('ascii', 0, 5) // outputs: abcde
buf.toString('utf8', 0, 5) // outputs: abcde
buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcde
還記得fs嗎?默認情況下 data 值也是緩衝區:
fs.readFile('/etc/passwd', function (err, data) {
if (err) return console.error(err)
console.log(data)
});
data 處理文件時是緩衝區。
集群
您可能經常聽到 Node 懷疑論者的論點,即它是單線程的,因此無法擴展。有一個核心模塊cluster (這意味著您不需要安裝它;它是平台的一部分),它允許您利用每台機器的所有 CPU 能力。這將允許您垂直擴展 Node 程序。
代碼非常簡單。我們需要導入模塊,創建一個master和多個worker。通常,我們創建的進程數量與我們擁有的 CPU 數量一樣多。這不是一成不變的規則。您可以根據需要擁有任意數量的新流程,但在某一點上,收益遞減定律開始發揮作用,您不會獲得任何性能提升。
master 和 worker 的代碼在同一個文件中。 worker 可以在同一個端口上偵聽並向 master 發送消息(通過事件)。 Master 可以根據需要監聽事件並重啟集群。給master寫代碼的方式是使用cluster.isMaster() ,對於工人來說是 cluster.isWorker() .服務器代碼將駐留在工作人員(isWorker() )。
// cluster.js
var cluster = require('cluster')
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
} else if (cluster.isWorker) {
// your server code
})
在 cluster.js 例如,我的服務器輸出進程 ID,因此您會看到不同的工作人員處理不同的請求。它就像一個負載均衡器,但它不是真正的負載均衡器,因為負載不會均勻分佈。您可能會看到更多的請求落在一個進程上(PID 將是相同的)。
要查看不同的工作人員處理不同的請求,請使用 loadtest 這是一個基於節點的壓力(或負載)測試工具:
- 安裝
loadtest使用 npm:$ npm install -g loadtest - 運行
code/cluster.js帶節點($ node cluster.js);讓服務器繼續運行 - 使用
$ loadtest http://localhost:3000 -t 20 -c 10運行負載測試 在新窗口中 - 在服務器終端和
loadtest上分析結果 終端 - 測試結束後,在服務器端按 control+c。您應該看到不同的 PID。記下服務的請求數。
-t 20 -c 10 在 loadtest 命令表示將有10個並發請求,最大時間為20秒。
核心集群是核心的一部分,這幾乎是它唯一的優勢。當您準備好部署到生產環境時,您可能需要使用更高級的流程管理器:
strong-cluster-control(https://github.com/strongloop/strong-cluster-control),或$ slc run:不錯的選擇pm2(https://github.com/Unitech/pm2):不錯的選擇
pm2
讓我們介紹一下 pm2 工具,它是垂直擴展 Node 應用程序的方法之一(最好的方法之一),並具有一些生產級性能和功能。
簡而言之,pm2有以下優點:
- 負載平衡器和其他功能
- 0s 重新加載停機時間,即永遠活著
- 良好的測試覆蓋率
您可以在 https://github.com/Unitech/pm2 和 http://pm2.keymetrics.io 找到 pm2 文檔。
看看這個 Express 服務器 (server.js ) 作為 pm2 示例。沒有樣板代碼 isMaster() 這很好,因為您不需要像我們使用 cluster 那樣修改源代碼 .我們在這台服務器上所做的只是 logpid 並保留他們的統計數據。
var express = require('express')
var port = 3000
global.stats = {}
console.log('worker (%s) is now listening to http://localhost:%s',
process.pid, port)
var app = express()
app.get('*', function(req, res) {
if (!global.stats[process.pid]) global.stats[process.pid] = 1
else global.stats[process.pid] += 1;
var l ='cluser '
+ process.pid
+ ' responded \n';
console.log(l, global.stats)
res.status(200).send(l)
})
app.listen(port)
啟動這個 pm2 例如,使用 pm2 start server.js .您可以傳遞要生成的實例/進程的數量(-i 0 表示與 CPU 數量一樣多,在我的情況下為 4 個)和記錄到文件的選項(-l log.txt ):
$ pm2 start server.js -i 0 -l ./log.txt

pm2 的另一個好處是它進入了前台。要查看當前正在運行的內容,請執行:
$ pm2 list
然後,利用 loadtest 就像我們在核心 cluster 中所做的那樣 例子。在新窗口中,運行以下命令:
$ loadtest http://localhost:3000 -t 20 -c 10
您的結果可能會有所不同,但我在 log.txt 中得到或多或少均勻分佈的結果 :
cluser 67415 responded
{ '67415': 4078 }
cluser 67430 responded
{ '67430': 4155 }
cluser 67404 responded
{ '67404': 4075 }
cluser 67403 responded
{ '67403': 4054 }
Spawn vs Fork vs Exec
由於我們使用了 fork() 在 cluter.js 以創建 Node 服務器的新實例為例,值得一提的是,有三種方法可以從 Node.js 內部啟動外部進程。它們是 spawn() , fork() 和 exec() ,並且這三個都來自核心child_process 模塊。不同之處可以總結如下:
require('child_process').spawn():用於大數據,支持流,可以與任何命令一起使用,並且不會創建新的 V8 實例require('child_process').fork()– 創建一個新的 V8 實例,實例化多個 worker,並且僅適用於 Node.js 腳本 (node命令)require('child_process').exec()– 使用一個不適合大數據或流式傳輸的緩衝區,以異步方式工作以在回調中一次獲取所有數據,並且可以與任何命令一起使用,而不僅僅是node
讓我們看一下執行 node program.js 的這個 spawn 示例 , 但該命令可以啟動 bash、Python、Ruby 或任何其他命令或腳本。如果您需要向命令傳遞其他參數,只需將它們作為數組的參數,該數組是 spawn() 的參數 .數據以 data 中的流形式出現 事件處理程序:
var fs = require('fs')
var process = require('child_process')
var p = process.spawn('node', 'program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
從node program.js的角度來看 命令,data 是它的標準輸出;即 node program.js 的終端輸出 .
fork() 的語法 與 spawn() 驚人地相似 方法有一個例外,沒有命令,因為 fork() 假設所有進程都是 Node.js:
var fs = require('fs')
var process = require('child_process')
var p = process.fork('program.js')
p.stdout.on('data', function(data)) {
console.log('stdout: ' + data)
})
本節議程的最後一項是 exec() .它略有不同,因為它不使用事件模式,而是使用單個回調。在裡面,你有錯誤、標準輸出和標準錯誤參數:
var fs = require('fs')
var process = require('child_process')
var p = process.exec('node program.js', function (error, stdout, stderr) {
if (error) console.log(error.code)
})
error的區別 和 stderr 是前者來自exec() (例如,program.js 的權限被拒絕 ),而後者來自您正在運行的命令的錯誤輸出(例如,數據庫連接在 program.js 內失敗 )。
處理異步錯誤
說到錯誤,在 Node.js 和幾乎所有編程語言中,我們都有 try/catch 我們用來處理錯誤。對於同步錯誤,try/catch 可以正常工作。
try {
throw new Error('Fail!')
} catch (e) {
console.log('Custom Error: ' + e.message)
}
模塊和函數會拋出我們稍後捕獲的錯誤。這適用於 Java 和 同步 節點。然而,最好的 Node.js 實踐是編寫 異步 代碼,這樣我們就不會阻塞線程。
事件循環是一種機制,它使系統能夠在完成昂貴的輸入/輸出任務時委託和安排將來需要執行的代碼。異步錯誤會出現問題,因為系統會丟失錯誤的上下文。
例如,setTimeout() 通過在將來安排回調來異步工作。它類似於發出 HTTP 請求、從數據庫讀取或寫入文件的異步函數:
try {
setTimeout(function () {
throw new Error('Fail!')
}, Math.round(Math.random()*100))
} catch (e) {
console.log('Custom Error: ' + e.message)
}
沒有try/catch 當執行回調並且應用程序崩潰時。當然,如果你再放一個 try/catch 在回調中,它會捕獲錯誤,但這不是一個好的解決方案。那些討厭的異步錯誤更難處理和調試。 Try/catch 對於異步代碼來說不夠好。
所以異步錯誤會使我們的應用程序崩潰。我們如何處理它們? ?您已經看到有一個 error 大多數回調中的參數。開發者需要在每個回調中檢查並冒泡(向上傳遞回調鍊或向用戶輸出錯誤消息):
if (error) return callback(error)
// or
if (error) return console.error(error)
處理異步錯誤的其他最佳實踐如下:
- 收聽所有“錯誤”事件
- 聽
uncaughtException - 使用
domain(軟棄用)或 AsyncWrap - 記錄、記錄、記錄和跟踪
- 通知(可選)
- 退出並重啟進程
on(‘錯誤’)
收聽所有 on('error') 大多數核心 Node.js 對象發出的事件,尤其是 http .此外,任何從 Express.js、LoopBack、Sails、Hapi 等繼承或創建實例的東西都會發出 error ,因為這些框架擴展了 http .
js
server.on('error', function (err) {
console.error(err)
console.error(err)
process.exit(1)
})
未捕獲異常
總是聽uncaughtException 在 process 目的! uncaughtException 是一種非常粗糙的異常處理機制。未處理的異常意味著您的應用程序——以及擴展的 Node.js 本身——處於未定義狀態。盲目復工意味著什麼都有可能發生。
process.on('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
})
或
process.addListener('uncaughtException', function (err) {
console.error('uncaughtException: ', err.message)
console.error(err.stack)
process.exit(1)
域
域與您在瀏覽器中看到的 Web 域無關。 domain 是一個 Node.js 核心模塊,通過保存實現異步代碼的上下文來處理異步錯誤。 domain 的基本用法 是實例化它並將你的崩潰代碼放入 run() 回調:
var domain = require('domain').create()
domain.on('error', function(error){
console.log(error)
})
domain.run(function(){
throw new Error('Failed!')
})
domain 在 4.0 中被輕微棄用,這意味著 Node 核心團隊很可能會分離 domain 來自平台,但目前在核心中沒有替代品。另外,因為 domain 具有強大的支持和使用,它將作為一個單獨的 npm 模塊存在,因此您可以輕鬆地從核心切換到 npm 模塊,這意味著 domain 在這裡留下來。
讓我們使用相同的 setTimeout() 使錯誤異步 :
// domain-async.js:
var d = require('domain').create()
d.on('error', function(e) {
console.log('Custom Error: ' + e)
})
d.run(function() {
setTimeout(function () {
throw new Error('Failed!')
}, Math.round(Math.random()*100))
});
代碼不會崩潰!我們會看到來自域的 error 的漂亮錯誤消息“自定義錯誤” 事件處理程序,而不是典型的 Node 堆棧跟踪。
C++ 插件
Node 在硬件、物聯網和機器人技術中流行的原因是它能夠很好地處理低級 C/C++ 代碼。那麼我們如何為您的 IoT、硬件、無人機、智能設備等編寫 C/C++ 綁定呢?
這是本文的最後一個核心特徵。大多數 Node 初學者甚至不認為您可以編寫自己的 C++ 插件!事實上,這很容易,我們現在就從頭開始。
首先,創建 hello.cc 開頭有一些樣板導入的文件。然後,我們定義一個返回字符串並導出該方法的方法。
#include <node.h>
namespace demo {
using v8::FunctionCallbackInfo;
using v8::HandleScope;
using v8::Isolate;
using v8::Local;
using v8::Object;
using v8::String;
using v8::Value;
void Method(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); // String
}
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method); // Exporting
}
NODE_MODULE(addon, init)
}
即使你不是 C 方面的專家,也很容易發現這裡發生了什麼,因為語法對 JavaScript 來說並不陌生。字符串是 capital one :
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one"));`
導出的名稱是 hello :
void init(Local<Object> exports) {
NODE_SET_METHOD(exports, "hello", Method);
}
一次 hello.cc 準備好了,我們還需要做一些事情。其中之一是創建 binding.gyp 其中有源代碼文件名和插件名稱:
{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}
保存 binding.gyp 在與 hello.cc 相同的文件夾中 並安裝 node-gyp :
$ npm install -g node-gyp
一旦你得到 node-gyp ,在您擁有 hello.cc 的同一文件夾中運行這些配置和構建命令 和 binding.gyp :
$ node-gyp configure
$ node-gyp build
這些命令將創建 build 文件夾。檢查已編譯的 .node build/Release/ 中的文件 .
最後,編寫創建 Node.js 腳本 hello.js ,並包含您的 C++ 插件:
var addon = require('./build/Release/addon')
console.log(addon.hello()) // 'capital one'
運行腳本並查看我們的字符串 capital one ,只需使用:
$ node hello.js
在 https://github.com/nodejs/node-addon-examples 有更多 C++ 插件示例。
總結
可以使用的代碼在 GitHub 上。如果您喜歡這篇文章,請在下面發表評論。如果您對觀察者、回調和節點約定等 Node.js 模式感興趣,請查看我的文章節點模式:從回調到觀察者。
我知道這是一篇很長的文章,所以這裡有一個 30 秒的摘要:
- 事件循環:Node 非阻塞 I/O 背後的機制
- 全局和進程:全局對象和系統信息
- 事件發射器:Node.js 的觀察者模式
- 流:大數據模式
- 緩衝區:二進制數據類型
- 集群:垂直縮放
- 域:異步錯誤處理
- C++ 插件:低級插件
Node 的大部分內容都是 JavaScript,除了一些主要處理系統訪問、全局、外部進程和低級代碼的核心功能。如果您理解了這些概念(請隨時保存這篇文章並再讀幾遍),您將走上一條快速而簡短地掌握 Node.js 的道路。