使用 Prometheus 和 Grafana 進行 Node.js 應用程序監控
監控應用程序
監控應用程序仍然是微服務世界的關鍵部分 .與監控微服務相關的挑戰通常是您的生態系統所獨有的,並且故障通常是謹慎的 - 一個小模塊的故障可能會在一段時間內被忽視。
如果我們研究一個更傳統的單體應用程序,作為單個可執行庫或服務安裝 - 故障通常更明確,因為它的模塊並不意味著作為獨立服務運行。
在開發過程中,最初通常不會過多考慮監控,因為通常需要處理更緊迫的問題。但是,一旦部署,尤其是當應用程序的流量開始增加時 - 監控瓶頸和系統的健康狀況對於在出現故障時快速周轉變得必要。
在本指南中,我們將研究 Prometheus 和 格拉法納 監控 Node.js 應用程序。我們將使用 Node.js 庫將有用的指標發送到 Prometheus,然後將它們導出到 Grafana 以進行數據可視化。
Prometheus - 具有 DevOps 思維方式的產品
Prometheus 是一個開源監控系統,也是雲原生計算基金會的成員。它最初是作為 SoundCloud 的內部監控解決方案而創建的 ,但現在由開發人員和用戶社區維護。
普羅米修斯的特點
Prometheus 的一些關鍵特性是:
- Prometheus 通過 HTTP 以預定義的時間間隔拉取指標端點,從服務器或設備收集指標。
- 一個多維時間序列數據模型 .簡而言之 - 它跟踪不同特徵/指標(維度)的時間序列數據。
- 它提供了一種專有的功能查詢語言,稱為 PromQL(Prometheus 查詢語言) . PromQL 可用於數據選擇和聚合。
- 推送網關 - 一個指標緩存,用於保存批處理作業的指標,這些指標的短壽命通常會使它們不可靠或無法通過 HTTP 定期抓取。
- 用於執行 PromQL 表達式並隨時間以表格或圖表的形式可視化結果的 Web 用戶界面。
- 它還提供警報功能,可在匹配定義的規則時向 Alertmanager 發送警報,並通過電子郵件或其他平台發送通知。
- 社區維護著許多幫助提取指標的第三方出口商和集成商。
架構圖
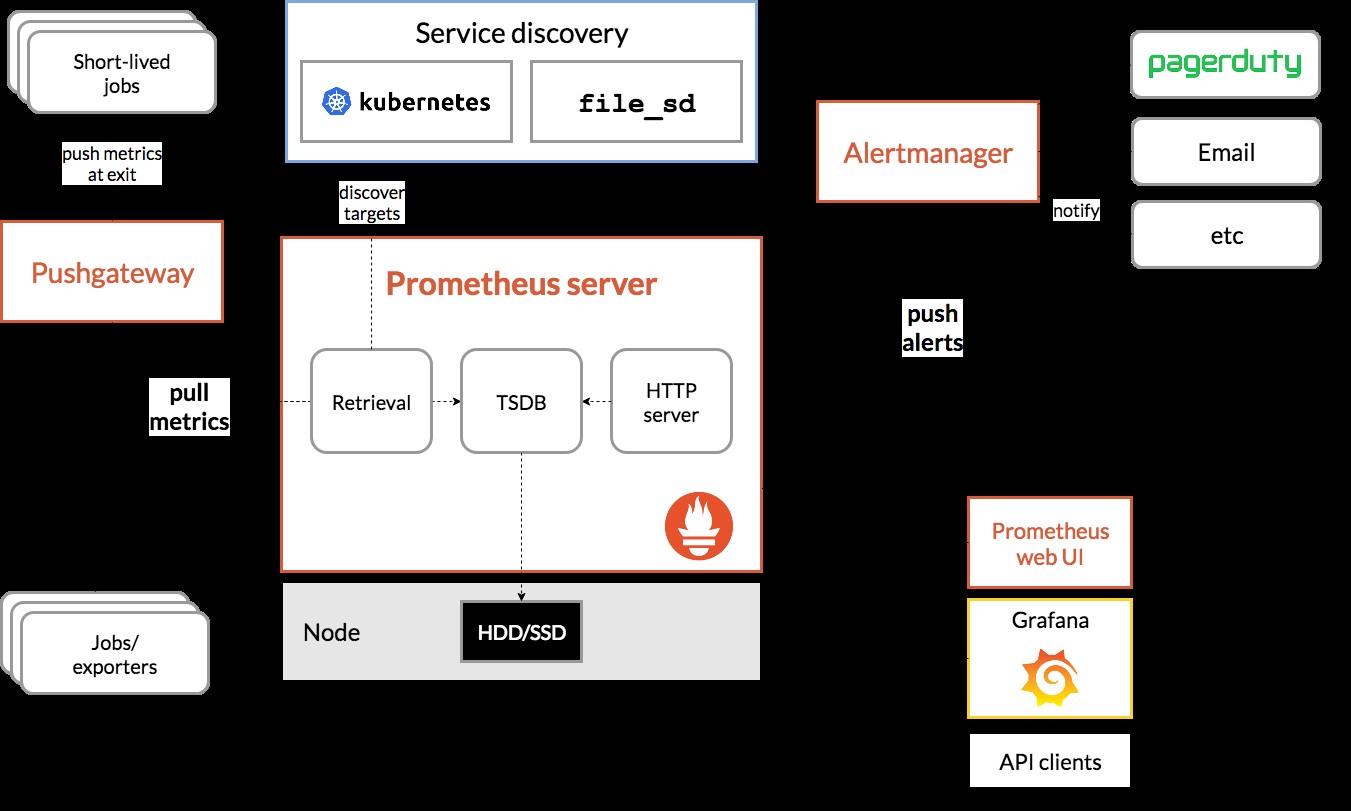
來源:Prometheus.io
介紹prom-client
Prometheus 在自己的服務器上運行。要將您自己的應用程序橋接到 Prometheus 服務器,您需要使用指標導出器,並公開指標,以便 Prometheus 可以通過 HTTP 拉取它們。
我們將依賴 prom-client 庫從我們的應用程序中導出指標。它支持生成直方圖、摘要、儀表和計數器所需的數據導出。
安裝prom-client
安裝prom-client的最簡單方法 模塊是通過 npm :
$ npm install prom-client
使用 prom-client 公開默認 Prometheus 指標
Prometheus 團隊有一套推薦 要跟踪的指標,prom-client 因此包括作為默認指標 ,可以通過collectDefaultMetrics()從客戶端獲取 .
這些指標包括虛擬內存大小、打開文件描述符的數量、所花費的總 CPU 時間等:
const client = require('prom-client');
// Create a Registry to register the metrics
const register = new client.Registry();
client.collectDefaultMetrics({register});
我們跟踪在 Registry 中收集的指標 - 所以在從客戶端收集默認指標時,我們傳入 Registry 實例。您還可以在 collectDefaultMetrics() 中提供其他自定義選項 來電:
const client = require('prom-client');
// Create a Registry to register the metrics
const register = new client.Registry();
client.collectDefaultMetrics({
app: 'node-application-monitoring-app',
prefix: 'node_',
timeout: 10000,
gcDurationBuckets: [0.001, 0.01, 0.1, 1, 2, 5],
register
});
在這裡,我們添加了我們的應用程序的名稱,一個 prefix 對於便於導航的指標,timeout 指定請求何時超時的參數以及 gcDurationBuckets 它定義了 垃圾收集直方圖 的桶應該有多大 .
收集任何其他指標遵循相同的模式 - 我們將通過 client 收集它們 然後將它們註冊到註冊表中。稍後會詳細介紹。
一旦指標位於寄存器中,我們就可以將它們返回 from Prometheus 將從中抓取的端點上的寄存器。讓我們創建一個 HTTP 服務器,公開一個 /metrics 端點,返回 metrics() 來自 register 命中時:
const client = require('prom-client');
const express = require('express');
const app = express();
// Create a registry and pull default metrics
// ...
app.get('/metrics', async (req, res) => {
res.setHeader('Content-Type', register.contentType);
res.send(await register.metrics());
});
app.listen(8080, () => console.log('Server is running on http://localhost:8080, metrics are exposed on http://localhost:8080/metrics'));
我們使用 Express.js 在端口 8080 公開端點 ,當被 GET 擊中時 請求從註冊表返回指標。自 metrics() 返回一個 Promise ,我們使用了 async /await 檢索結果的語法。
如果您不熟悉 Express.js - 請閱讀我們的使用 Node.js 和 Express 構建 REST API 指南。
讓我們繼續發送一個 curl 對這個端點的請求:
$ curl -GET localhost:8080/metrics
# HELP node_process_cpu_user_seconds_total Total user CPU time spent in seconds.
# TYPE node_process_cpu_user_seconds_total counter
node_process_cpu_user_seconds_total 0.019943
# HELP node_process_cpu_system_seconds_total Total system CPU time spent in seconds.
# TYPE node_process_cpu_system_seconds_total counter
node_process_cpu_system_seconds_total 0.006524
# HELP node_process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE node_process_cpu_seconds_total counter
node_process_cpu_seconds_total 0.026467
# HELP node_process_start_time_seconds Start time of the process since unix epoch in seconds.
...
指標由一堆組成 有用的指標,每個指標都通過評論進行解釋。不過,回到介紹中的陳述——在很多情況下,您的監控需求可能是特定於生態系統的。值得慶幸的是,您也可以完全靈活地公開自己的自定義指標。
使用 prom-client 公開自定義指標
儘管公開默認指標是了解框架以及您的應用程序的一個很好的起點 - 在某些時候,我們需要定義自定義指標以在一些請求流中使用鷹眼。
讓我們創建一個跟踪 HTTP 請求持續時間的指標。為了模擬某個端點上的繁重操作,我們將創建一個需要 3-6 秒才能返迴響應的模擬操作。我們將可視化響應時間的直方圖及其分佈。我們還將考慮路線及其返回代碼。
要註冊和跟踪這樣的指標 - 我們將創建一個新的 Histogram 並使用 startTimer() 啟動計時器的方法。 startTimer() 的返回類型 方法是另一個你可以調用來觀察的函數 (記錄)記錄的指標並結束計時器,傳入您希望與直方圖的指標相關聯的標籤。
你可以手動observe() 但是,調用返回的方法更容易、更簡潔。
讓我們先創建一個自定義 Histogram 為此:
// Create a custom histogram metric
const httpRequestTimer = new client.Histogram({
name: 'http_request_duration_seconds',
help: 'Duration of HTTP requests in seconds',
labelNames: ['method', 'route', 'code'],
buckets: [0.1, 0.3, 0.5, 0.7, 1, 3, 5, 7, 10] // 0.1 to 10 seconds
});
// Register the histogram
register.registerMetric(httpRequestTimer);
注意: buckets 只是我們直方圖的標籤,指的是請求的長度。如果請求時間少於 0.1s 執行,它屬於0.1 桶。
每次我們想對一些請求進行計時並記錄它們的分佈時,我們都會引用這個實例。我們還定義一個延遲處理程序,它會延遲響應,從而模擬一個繁重的操作:
// Mock slow endpoint, waiting between 3 and 6 seconds to return a response
const createDelayHandler = async (req, res) => {
if ((Math.floor(Math.random() * 100)) === 0) {
throw new Error('Internal Error')
}
// Generate number between 3-6, then delay by a factor of 1000 (miliseconds)
const delaySeconds = Math.floor(Math.random() * (6 - 3)) + 3
await new Promise(res => setTimeout(res, delaySeconds * 1000))
res.end('Slow url accessed!');
};
最後,我們可以定義我們的 /metrics 和 /slow 其中一個端點使用延遲處理程序來延遲響應。這些中的每一個都將使用我們的 httpRequestTimer 進行計時 實例,並記錄:
// Prometheus metrics route
app.get('/metrics', async (req, res) => {
// Start the HTTP request timer, saving a reference to the returned method
const end = httpRequestTimer.startTimer();
// Save reference to the path so we can record it when ending the timer
const route = req.route.path;
res.setHeader('Content-Type', register.contentType);
res.send(await register.metrics());
// End timer and add labels
end({ route, code: res.statusCode, method: req.method });
});
//
app.get('/slow', async (req, res) => {
const end = httpRequestTimer.startTimer();
const route = req.route.path;
await createDelayHandler(req, res);
end({ route, code: res.statusCode, method: req.method });
});
// Start the Express server and listen to a port
app.listen(8080, () => {
console.log('Server is running on http://localhost:8080, metrics are exposed on http://localhost:8080/metrics')
});
免費電子書:Git Essentials
查看我們的 Git 學習實踐指南,其中包含最佳實踐、行業認可的標準以及隨附的備忘單。停止谷歌搜索 Git 命令並真正學習 它!
現在,每次我們向 /slow 發送請求 端點,或 /metrics 端點 - 請求持續時間被記錄並添加到 Prometheus 的註冊表中。順便說一句,我們也公開 /metrics 上的這些指標 端點。讓我們發送一個 GET 請求 /slow 然後觀察 /metrics 再次:
$ curl -GET localhost:8080/slow
Slow url accessed!
$ curl -GET localhost:8080/metrics
# HELP http_request_duration_seconds Duration of HTTP requests in seconds
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.1",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="0.3",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="0.5",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="0.7",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="1",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="3",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="5",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="7",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="10",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="+Inf",route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_sum{route="/metrics",code="200",method="GET"} 0.0042126
http_request_duration_seconds_count{route="/metrics",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="0.1",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="0.3",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="0.5",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="0.7",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="1",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="3",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="5",route="/slow",code="200",method="GET"} 0
http_request_duration_seconds_bucket{le="7",route="/slow",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="10",route="/slow",code="200",method="GET"} 1
http_request_duration_seconds_bucket{le="+Inf",route="/slow",code="200",method="GET"} 1
http_request_duration_seconds_sum{route="/slow",code="200",method="GET"} 5.0022148
http_request_duration_seconds_count{route="/slow",code="200",method="GET"} 1
直方圖有幾個桶並跟踪 route , code 和 method 我們曾經訪問過端點。花了 0.0042126 訪問 /metrics 的秒數 ,但是一個巨大的 5.0022148 訪問 /slow 端點。現在,即使這是一個非常小的日誌,也只能跟踪兩個端點的單個請求 - 這看起來並不容易。人類並不擅長消化這樣的大量信息 - 所以最好參考這些數據的可視化。
為此,我們將使用 Grafana 使用 /metrics 中的指標 端點並可視化它們。 Grafana 與 Prometheus 非常相似,在自己的服務器上運行,將它們與我們的 Node.js 應用程序一起運行的簡單方法是通過 Docker Compose 集群 .
Docker Compose 集群設置
讓我們從創建一個 docker-compose.yml 開始 我們將使用該文件讓 Docker 知道如何啟動並公開 Node.js 服務器、Prometheus 服務器和 Grafana 服務器的相應端口。由於 Prometheus 和 Grafana 可以作為 Docker 鏡像使用,我們可以直接從 Docker Hub 中拉取它們的鏡像:
version: '2.1'
networks:
monitoring:
driver: bridge
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus:v2.20.1
container_name: prometheus
volumes:
- ./prometheus:/etc/prometheus
- prometheus_data:/prometheus
ports:
- 9090:9090
expose:
- 9090
networks:
- monitoring
grafana:
image: grafana/grafana:7.1.5
container_name: grafana
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning
environment:
- GF_AUTH_DISABLE_LOGIN_FORM=true
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
ports:
- 3000:3000
expose:
- 3000
networks:
- monitoring
node-application-monitoring-app:
build:
context: node-application-monitoring-app
ports:
- 8080:8080
expose:
- 8080
networks:
- monitoring
Node 應用程序正在端口 8080 上公開 , Grafana 暴露在 3000 Prometheus 暴露在 9090 .或者,您可以克隆我們的 GitHub 存儲庫:
$ git clone https://github.com/StackAbuse/node-prometheus-grafana.git
如果您不確定哪些配置文件應該位於哪些目錄中,您也可以參考存儲庫。
使用 docker-compose 可以一次啟動所有 docker 容器 命令。作為先決條件,無論您想在 Windows、Mac 還是 Linux 機器上託管此集群,都需要安裝 Docker Engine 和 Docker Compose。
注意: 如果您想了解更多關於 Docker 和 Docker Compose 的信息,可以閱讀我們的 Docker 指南:高級介紹或 Docker 如何讓您的開發人員生活更輕鬆。
安裝完成後,可以在項目根目錄下運行如下命令:
$ docker-compose up -d
執行此命令後,三個應用程序將在後台運行 - Node.js 服務器、Prometheus Web UI 和服務器以及 Grafana UI。
配置 Prometheus 以抓取指標
Prometheus 以給定的時間間隔抓取相關端點。知道什麼時候刮,以及在哪裡 ,我們需要創建一個配置文件 - prometheus.yml :
global:
scrape_interval: 5s
scrape_configs:
- job_name: "node-application-monitoring-app"
static_configs:
- targets: ["docker.host:8080"]
注意: docker.host 需要替換為docker-compose中配置的Node.js服務器的實際主機名 YAML 文件。
在這裡,我們安排它每 5 秒抓取一次指標。默認情況下,全局設置為 15 秒,因此我們將其設置得更頻繁一些。作業名稱是為了我們自己的方便和識別我們正在密切關注的應用程序。最後,/metrics 目標的端點是普羅米修斯將窺視的。
為 Grafana 配置數據源
在我們配置 Prometheus 的同時——讓我們也創建一個 數據源 為格拉法納。如前所述,並將進一步闡述 - 它接受來自數據源的數據並將其可視化。當然,這些數據源需要符合一些協議和標準。
datasources.yml 文件包含有關 Grafana 的所有數據源的配置。我們只有一個 - 我們的 Prometheus 服務器,暴露在端口 9090 :
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://docker.prometheus.host:9090
basicAuth: false
isDefault: true
editable: true
注意: docker.prometheus.host 將替換為 docker-compose 中配置的實際 Prometheus 主機名 YAML 文件。
模擬生產級流量
最後,如果我們在應用程序上生成一些合成流量,則最容易查看結果。您可以簡單地多次重新加載頁面,或發送許多請求,但由於手動操作會很耗時 - 您可以使用任何各種工具,例如 ApacheBench、ali、API Bench 等。
我們的 Node.js 應用程序將使用 prom-client 記錄這些並將它們提交到 Prometheus 服務器。剩下的就是使用 Grafana 將它們可視化。
Grafana - 易於設置的儀表板
Grafana 是一個用於監控和可視化各種指標的分析平台。它允許您為其數據源添加自定義查詢、可視化、提醒和了解您的指標,無論它們存儲在哪裡。您可以創建、探索和與您的團隊共享儀表板,並培養一種數據驅動的文化。
Grafana 監控儀表板
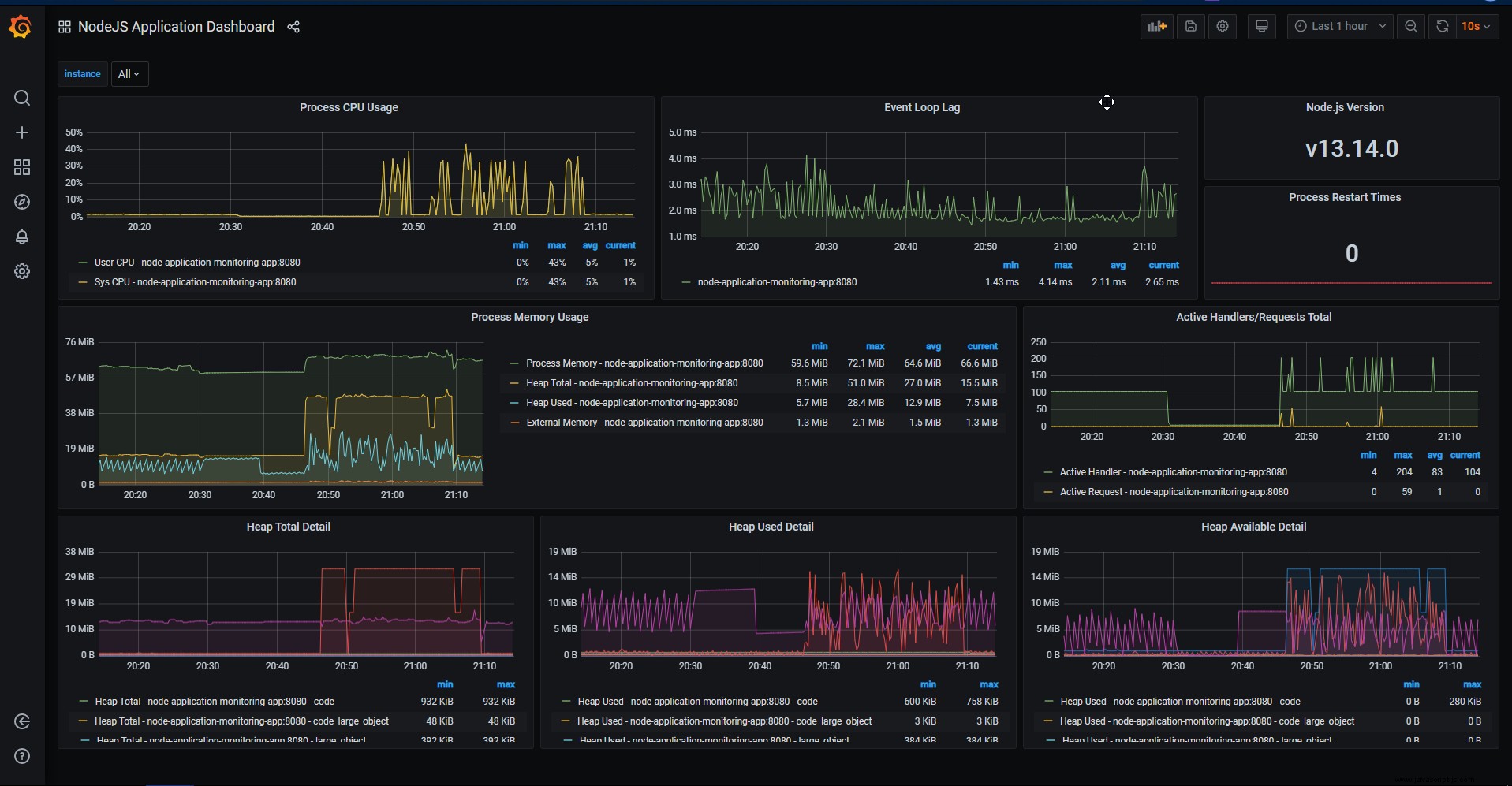
一些儀表板是開箱即用的,以提供正在發生的事情的概述。 NodeJS 應用程序儀表板 收集默認指標並將其可視化:
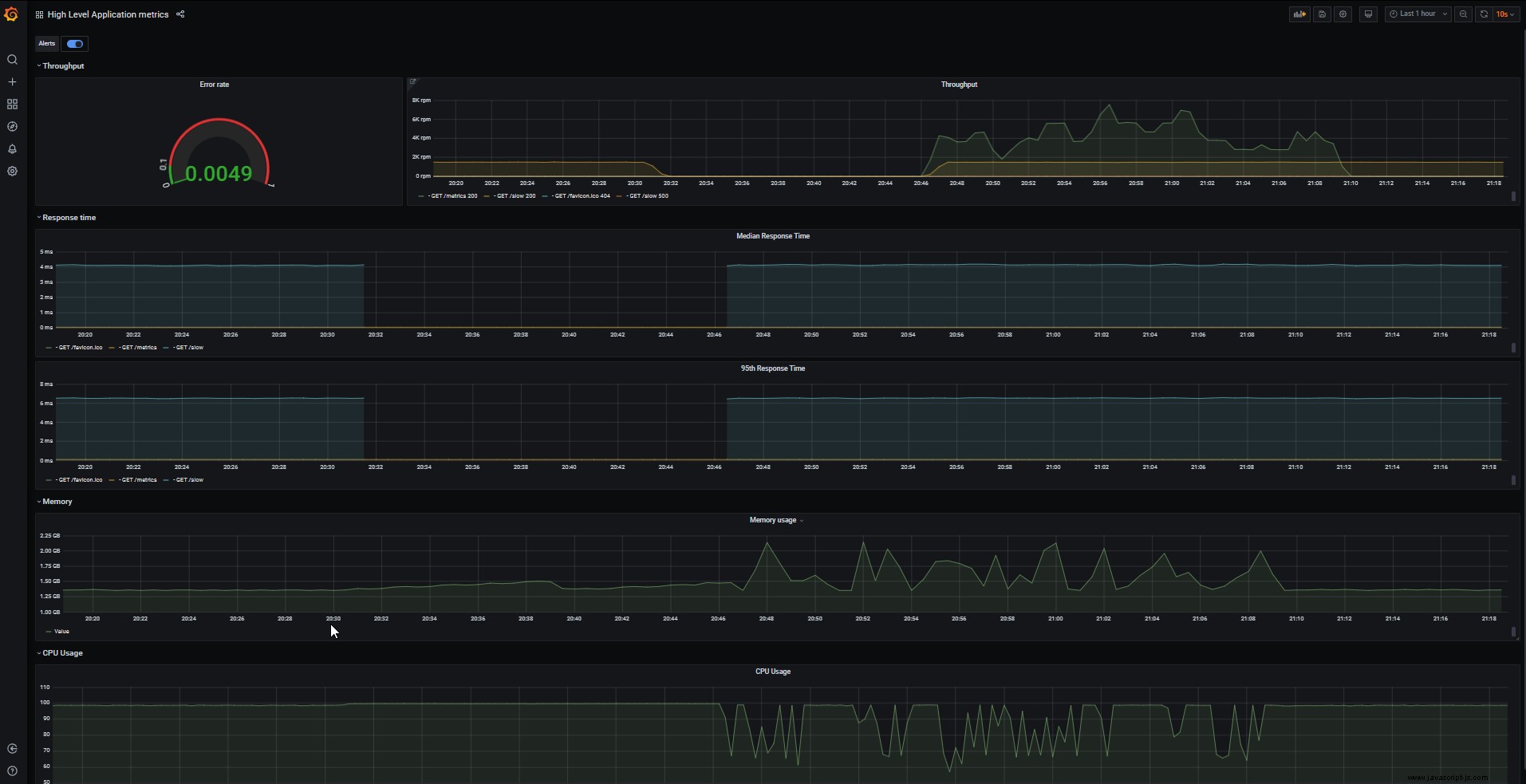
高級應用程序指標 儀表板使用錯誤率、CPU 使用率、內存使用率等默認指標顯示 Node.js 應用程序的高級指標:
請求流儀表板 使用我們在 Node.js 應用程序中創建的 API 顯示請求流指標。也就是說,這裡是 Histogram 我們創造了閃耀:
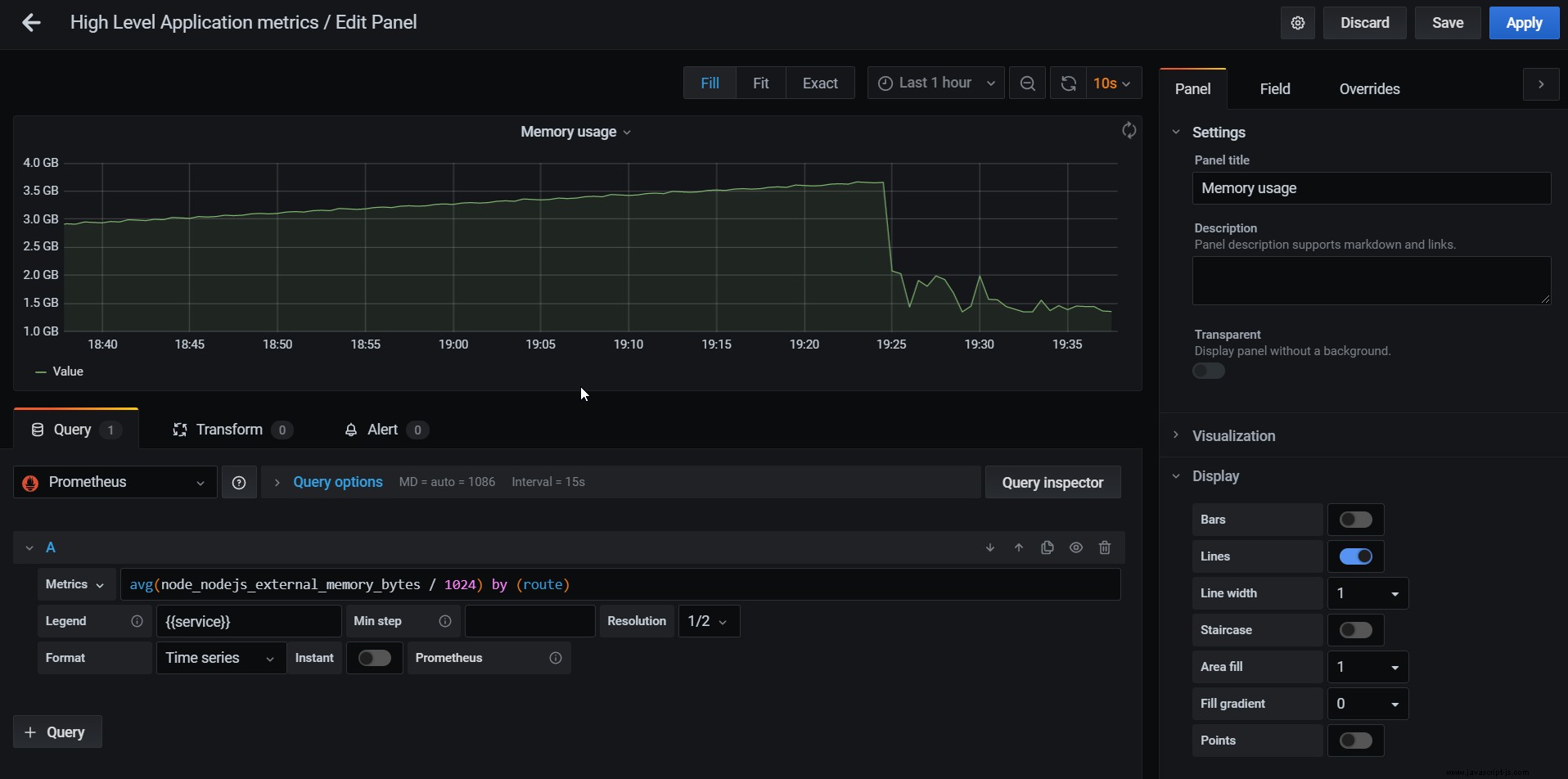
內存使用圖表
除了開箱即用的儀表板,您還可以創建聚合來計算不同的指標。例如,我們可以通過以下方式計算內存使用量:
avg(node_nodejs_external_memory_bytes / 1024) by (route)
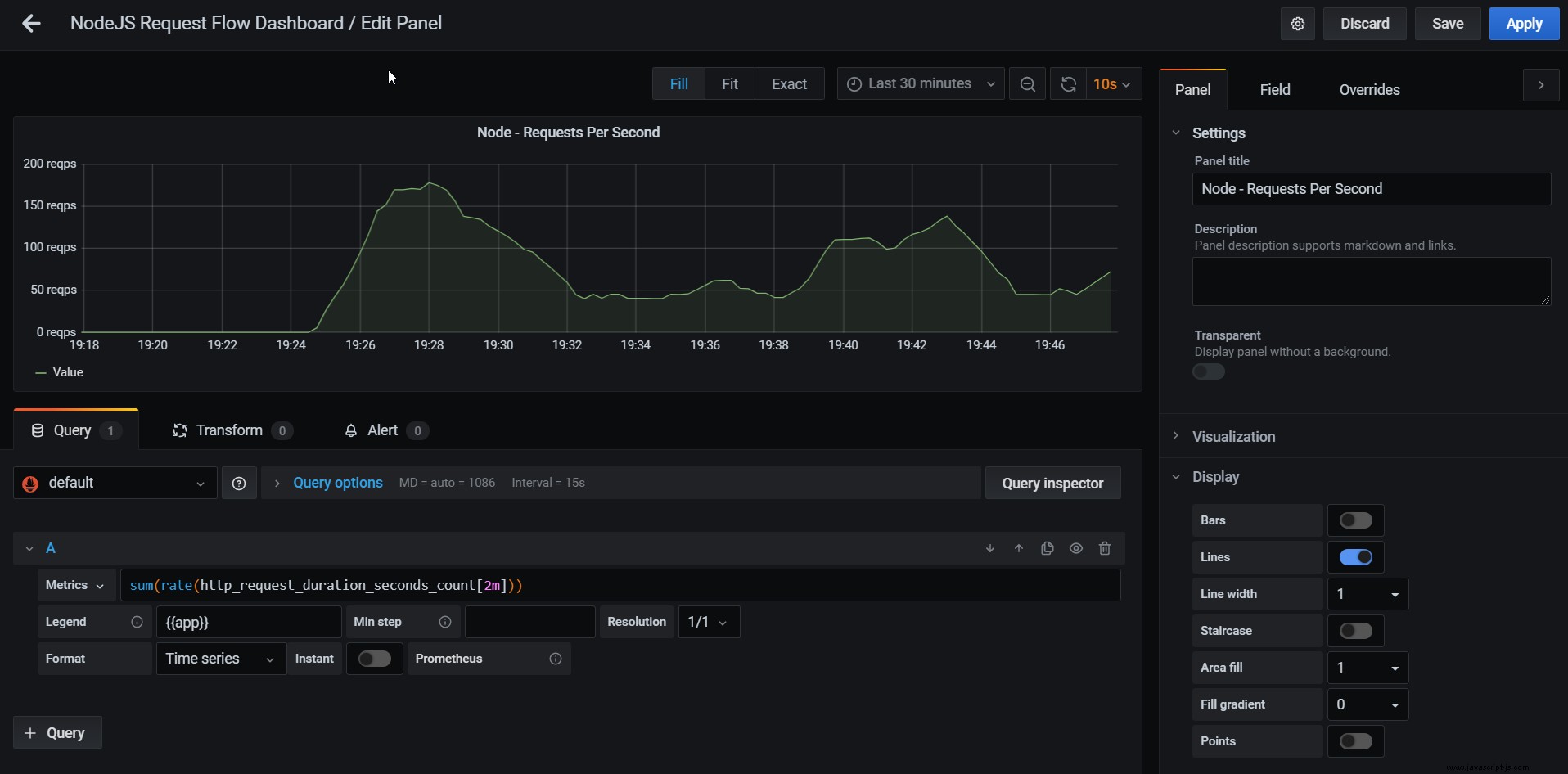
請求每秒直方圖
或者,我們可以使用來自我們自己的數據收集器的數據繪製一個顯示每秒請求數的圖表(以 2 分鐘為間隔):
sum(rate(http_request_duration_seconds_count[2m]))
結論
Prometheus 和 Grafana 是用於應用程序監控的強大開源工具。憑藉活躍的社區以及許多客戶端庫和集成,幾行代碼就可以對系統帶來非常簡潔明了的洞察力。