Node.js 應用程序中的緩存
緩存是將數據存儲在高速存儲層中的過程,以便將來對此類數據的請求可以比通過訪問其主存儲位置更快地完成。您可能熟悉的緩存示例是瀏覽器緩存,它將經常訪問的網站資源存儲在本地,因此不必每次需要時都通過網絡檢索它們。通過在用戶硬件上維護對象緩存,緩存數據的檢索幾乎是即時的,從而提高了速度和用戶滿意度。
在服務器端應用程序的上下文中,緩存旨在通過重用以前檢索或計算的數據來提高應用程序的響應時間。例如,您可以在初始請求後將數據存儲在緩存中,並在後續請求中從那裡檢索,而不是重複網絡請求以獲取不經常或根本不更改的數據(例如您所在國家/地區的銀行列表) .這使得後續對該數據的請求速度提高了一個數量級,從而提高了應用程序性能、降低了成本並加快了事務處理速度。
本文旨在概述緩存、緩存策略以及目前市場上可用的解決方案。閱讀這篇文章後,您應該對何時緩存、緩存什麼以及在 Node.js 應用程序中使用的適當技術有了更好的了解,具體取決於用例。
緩存的好處
緩存的主要好處是它通過減少重新計算結果或訪問底層處理或存儲層的需要來提高數據檢索的速度。更快的數據訪問顯著提高了應用程序的響應能力和性能,而無需添加新的硬件資源。其他好處包括:
-
減少服務器負載 :某些請求可能需要服務器上相當長的處理時間。如果查詢的結果已經存在於緩存中,則可以完全跳過此處理,從而使響應時間更快,從而騰出服務器資源來做其他工作。
-
提高可靠性 :檢索數據時延遲較高是應用程序使用量激增導致整體性能下降的常見影響。將大部分負載重定向到緩存層有助於提高性能的可預測性。
-
降低網絡成本 :將經常訪問的對象放在緩存中減少了必須在緩存之外執行的網絡活動量。這樣可以大大減少與內容源之間傳輸的數據,從而降低傳輸成本、減少網絡交換機隊列中的擁塞、減少丟包等。
-
改進的數據庫性能 :調查應用程序性能時的一個常見發現是,整個響應時間的很大一部分都花在了數據庫層上。即使查詢是高效的,處理每個查詢的成本(尤其是對於頻繁訪問的對象)也會迅速增加更高的延遲。緩解此問題的一個好方法是完全繞過查詢處理並使用緩存中的預計算結果。
-
增加內容的可用性 :緩存可用作保留某些數據可用性的一種方式,即使在原始數據存儲暫時關閉時也是如此。
什麼時候應該緩存?
緩存是提高性能的一個很好的工具,上一節討論的好處證明了這一點。那麼,什麼時候應該考慮在應用架構中添加緩存層呢?有幾個因素需要考慮。
大多數應用程序都有定期查詢但很少更新的數據熱點。例如,如果您在經營一個在線論壇,可能會有源源不斷的新帖子,但舊帖子將保持不變,許多舊帖子將長期保持不變。在這種情況下,應用程序可以接收數百或數千個對相同未更改數據的請求,這使其成為緩存的理想候選者。一般來說,經常訪問且不經常更改或根本不更改的數據應該存儲在緩存中。
決定緩存什麼時的另一個考慮因素是應用程序是否需要在返回或呈現某些數據之前執行複雜的查詢或計算。對於大容量網站,即使是在檢索和計算所需數據後呈現一些 HTML 輸出的簡單行為也會消耗大量資源並增加延遲。如果返回的輸出在計算後可以在多個查詢和操作中重複使用,那麼將其存儲在緩存中通常是一個好主意。
一條數據更改的速率以及可以容忍過時數據的時間長短也決定了它的可緩存性。如果數據頻繁更改以致無法在後續查詢中重複使用,那麼將其放入緩存中所需的開銷可能不值得。在這種情況下應該考慮其他類型的優化。
緩存可能是提高應用程序性能的好方法,但它不一定在每種情況下都是正確的做法。與所有性能優化技術一樣,重要的是在進行重大更改之前先進行測量,以免浪費時間優化錯誤的東西。
第一步是在給定的請求率下觀察相關係統的狀態和性能。如果系統無法跟上預期的負載,或者如果它受到限製或遭受高延遲,那麼緩存系統正在使用的數據可能是一個好主意,如果這樣的緩存會在多個請求中產生高命中率.
要考慮的緩存策略
緩存策略是一種用於管理緩存信息的模式,包括如何填充和維護緩存。有多種策略可供探索,選擇正確的策略對於獲得最大的性能優勢至關重要。聚合併返回實時排行榜的遊戲服務所採用的策略與提供其他類型數據(例如每天更新幾次的 COVID-19 統計數據)的服務有很大不同。
在選擇緩存解決方案之前,需要考慮三個主要事項:
- 緩存的數據類型。
- 如何讀取和寫入數據(數據訪問策略)。
- 緩存如何驅逐舊的或過時的數據(驅逐策略)。
在下一節中,我們將討論根據緩存數據類型可以採用的各種數據訪問策略。
數據訪問模式
採用的數據訪問模式決定了數據源和緩存層之間的關係。因此,正確處理這部分很重要,因為它可以對緩存的有效性產生重大影響。在本節的其餘部分,我們將討論常見的數據訪問模式,以及它們的優缺點。
1。緩存模式
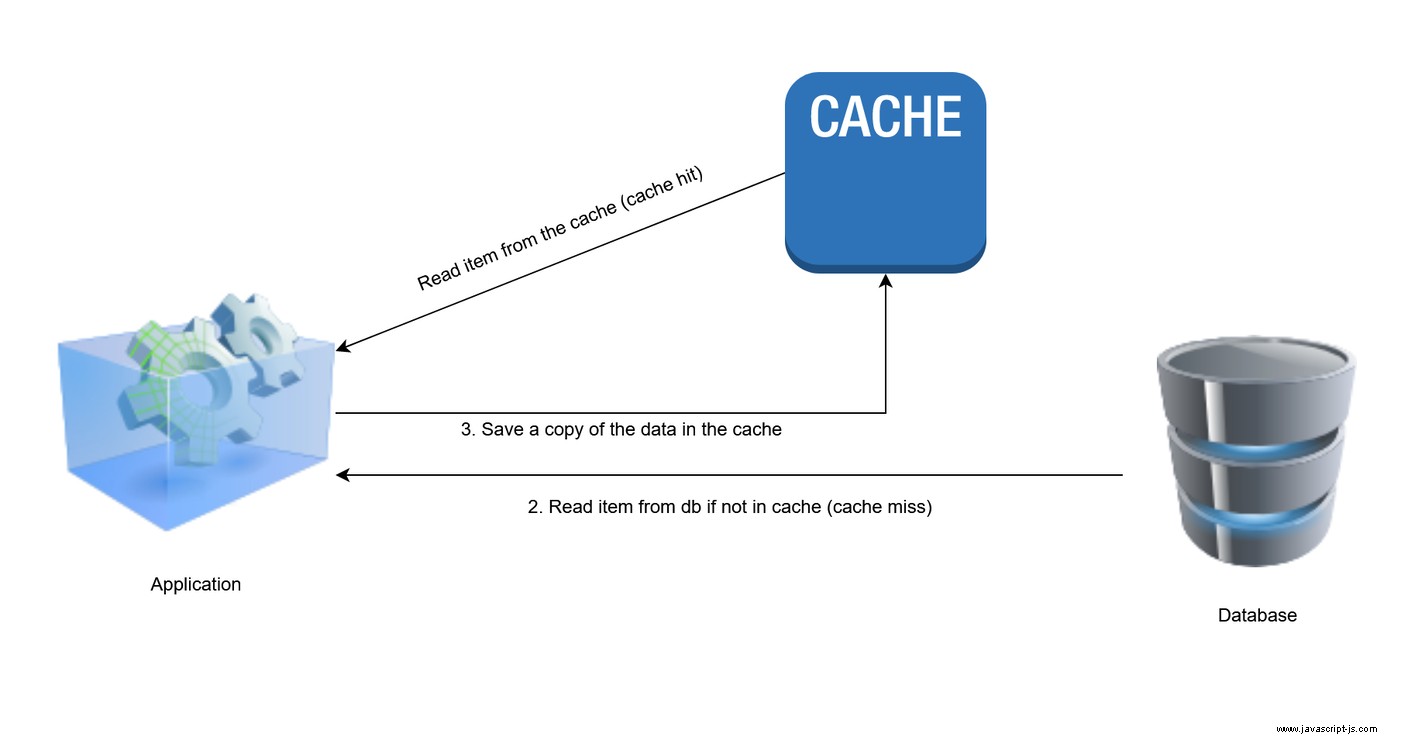
在緩存端模式中,僅在必要時才將數據加載到緩存中。每當客戶端請求數據時,應用程序首先檢查緩存層以查看數據是否存在。如果在緩存中找到數據,則將其檢索並返回給客戶端。這被稱為 緩存命中 .如果緩存中不存在數據(緩存未命中 ),應用程序將查詢數據庫以讀取請求的數據並將其返回給客戶端。之後,將數據存儲在緩存中,以便後續對相同數據的請求可以更快地得到解決。
以下是緩存側邏輯的偽代碼示例。
function makeAQuery(key) {
// Try to get the entity from the cache.
let data = cache.get(key);
// If there's a cache miss, get the data from the original store and cache it.
if (data == null) {
data = db.get(key)
// then store the data to cache with an appropriate expiry time
// to prevent staleness
cache.set(key, data, cache.defaultTTL)
}
// return the data to the application
return data;
}
// application code that gets the data
const data = makeAQuery(12345)
優勢
- 僅緩存請求的數據。這意味著緩存不會被從未使用過的數據填滿。
- 它最適合讀取繁重的工作流程,在這些工作流程中,數據寫入一次,讀取多次,然後再次更新(如果有的話)。
- 它對緩存故障具有彈性。如果緩存層不可用,系統將回退到數據存儲。請記住,長時間的緩存故障可能會導致延遲增加。
- 緩存中的數據模型不必映射到數據庫中的數據模型。例如,多個數據庫查詢的結果可以存儲在緩存中的同一個 id 下。
缺點
- 緩存未命中可能會增加延遲,因為執行了三個操作:
- 從緩存中請求數據。
- 從數據存儲中讀取數據。
- 將數據寫入緩存。
- 它不保證數據存儲和緩存之間的一致性。如果數據在數據庫中更新,它可能不會立即反映在緩存中,這會導致應用程序提供陳舊的數據。為了防止這種情況發生,緩存側模式通常與直寫策略(下文討論)結合使用,其中數據在數據庫和緩存中同時更新,以防止緩存數據過時。
2。通讀模式
在通讀緩存中,始終從緩存中讀取數據。當應用程序向緩存請求一個條目,但它還沒有在緩存中時,它會從底層數據存儲中加載並添加到緩存中以供將來使用。與緩存側模式不同,應用程序無需承擔直接讀取和寫入數據庫的責任。
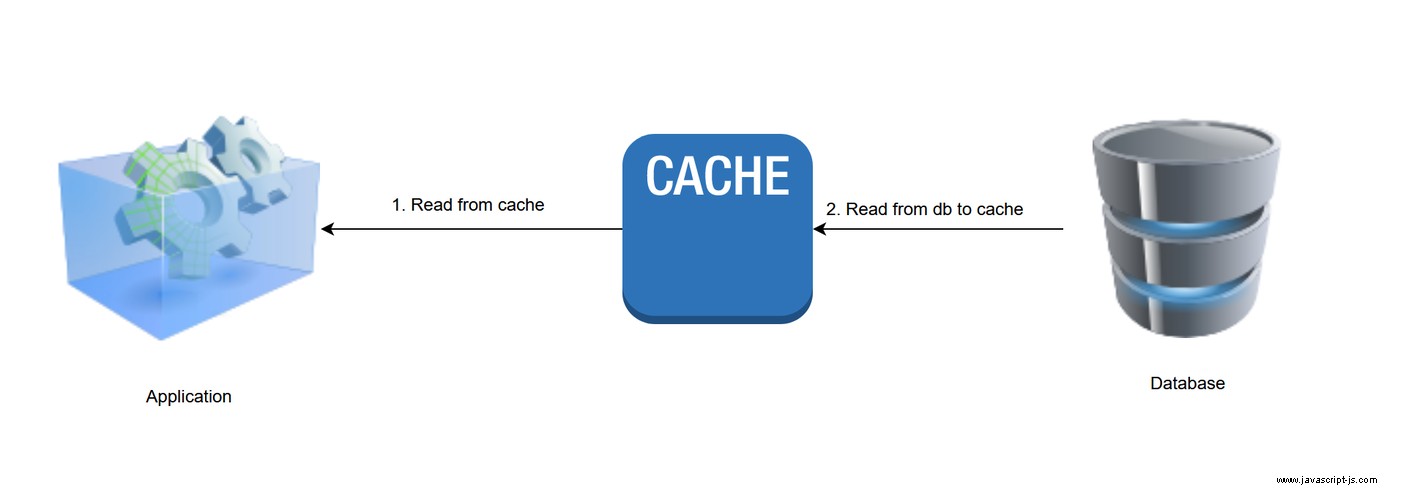
在大多數情況下,您需要實現緩存提供的通讀處理程序,它允許它在緩存未命中的情況下直接從數據庫中讀取數據。下面是一些偽代碼,演示了它是如何完成的:
// register the function that will be executed on cache misses.
cache.onmiss = (key) => {
return db.get(key) // return data from the database
};
// Actual data from the cache or onmiss handler
// A cache entry is created automatically on cache misses
// through the key and time-to-live values after the data
// is retrieved from the database
const data = cache.readThrough(key, data, ttl);
優勢
- 與緩存側一樣,它適用於多次請求相同數據的讀取繁重的工作負載。
- 只緩存請求的數據,支持資源的有效利用。
- 此模型允許緩存在數據更新或緩存條目過期時自動刷新數據庫中的對象。
缺點
- 緩存中的數據模型不能與數據庫中的數據模型不同。
- 與緩存側不同,它無法應對緩存故障。
- 當請求的數據不在緩存中時,延遲可能會增加。
- 緩存數據可能會變得陳舊,但可以通過使用以下考慮的寫入策略之一來解決此問題。
3。直寫模式
當採用直寫策略時,緩存層被視為應用程序的主要數據存儲。這意味著將新的或更新的數據直接添加或更新到緩存中,而將數據持久保存到底層數據存儲的任務委託給緩存層。兩個寫操作必須在一個事務中完成,以防止緩存數據與數據庫不同步。
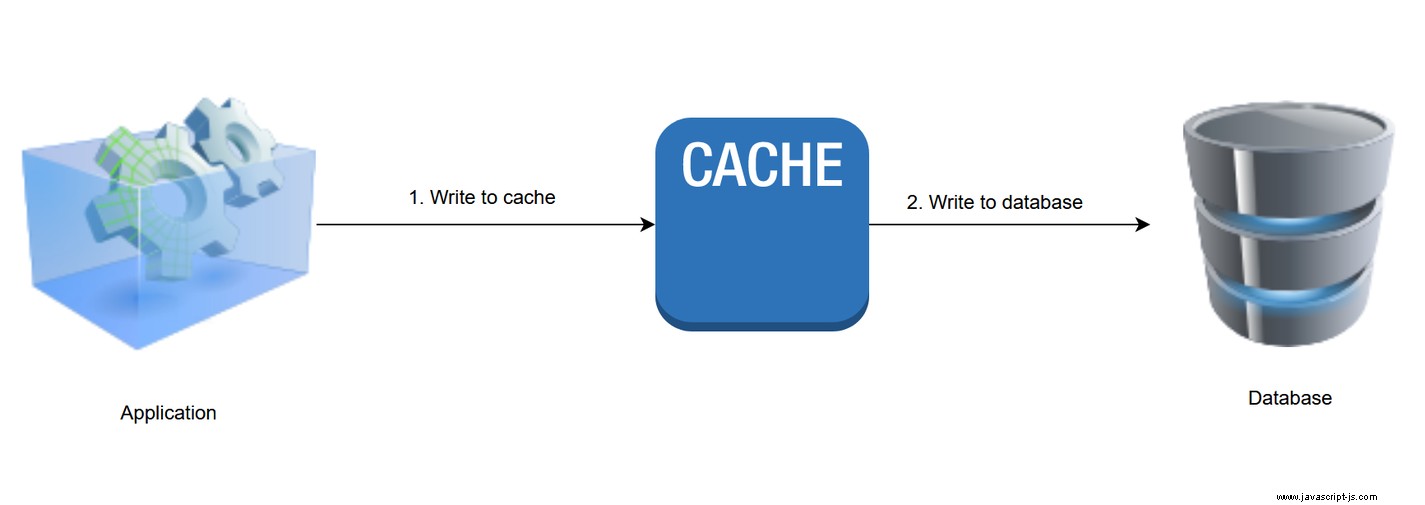
以下是直寫邏輯的偽代碼示例。
function updateCustomer(customerId, customerData) {
// the callback function will be executed after updating the
// record in the cache
cache.writeThrough(customerId, customerData, cache.defaultTTL, (key, value) => {
return db.save(key, value) // save updated data to db
});
}
// A variant is of this pattern is when updated in the db first
// and immediately updated in the cache
function updateCustomer(customerId, customerData) {
// update the record in the database first
const record = db.findAndUpdate(customerId, customerData)
// then set or update the record in the cache
cache.set(customerId, record, cache.defaultTTL)
}
優勢
- 緩存中的數據永遠不會過時,因為它在每次寫入操作後都會與數據庫同步。
- 它適用於不能容忍緩存陳舊的系統。
缺點
- 它會在寫入數據時增加延遲,因為通過先寫入數據存儲然後寫入緩存來完成更多工作。
- 如果緩存層不可用,寫入操作將失敗。
- 緩存可能會堆積從未讀取過的數據,這會浪費資源。可以通過將此模式與緩存端模式相結合或添加生存時間 (TTL) 策略來緩解這種情況。
4。後寫模式
在 write-behind 模式(也稱為 write-back)中,數據直接插入或修改到緩存中,然後在配置延遲後異步寫入數據源,延遲可能短至幾秒或長至幾天。採用這種緩存模式的主要含義是在緩存事務完成後的某個時間應用數據庫更新,這意味著您必須保證數據庫寫入將成功完成或提供回滾更新的方法。
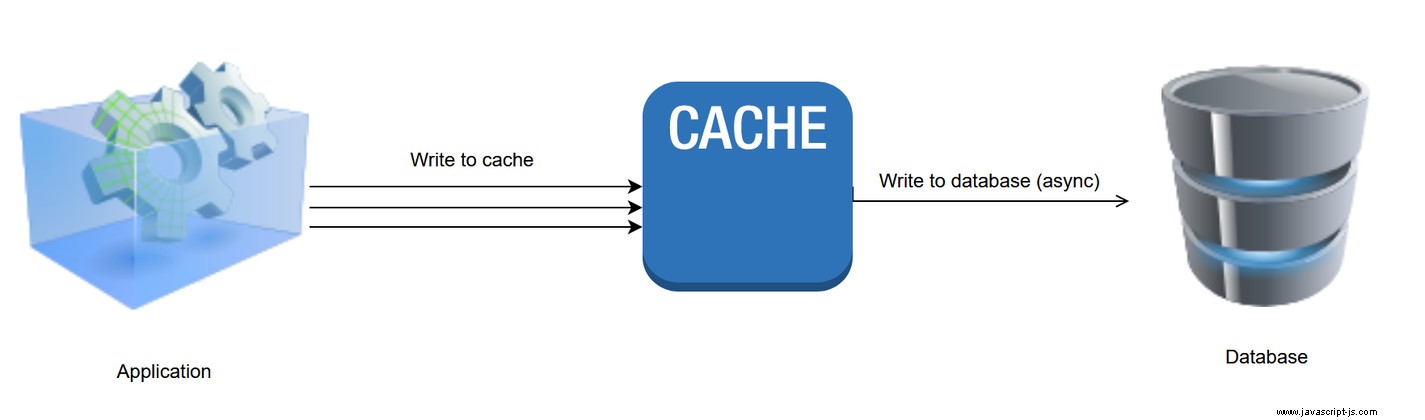
優勢
- 與直寫相比提高了寫入性能,因為應用不必等待數據寫入底層數據存儲。
- 由於經常將多次寫入批處理到單個數據庫事務中,因此減少了數據庫負載,如果請求數量是數據庫提供商定價的一個因素,這也可以降低成本。
- 應用程序受到一定程度的保護,不會出現臨時數據庫故障,因為失敗的寫入可以重新排隊。
- 它最適合寫入繁重的工作負載。
缺點
- 如果出現緩存故障,數據可能會永久丟失。因此,它可能不適合敏感數據。
- 直接在數據庫上執行的操作可能會利用陳舊的數據,因為無法保證緩存和數據存儲在任何給定時間點都是一致的。
5。提前刷新模式
在預刷新模式中,頻繁訪問的緩存數據在過期之前被刷新。這是異步發生的,因此當對象過期時從數據存儲中檢索對象時,應用程序不會感受到緩慢讀取的影響。
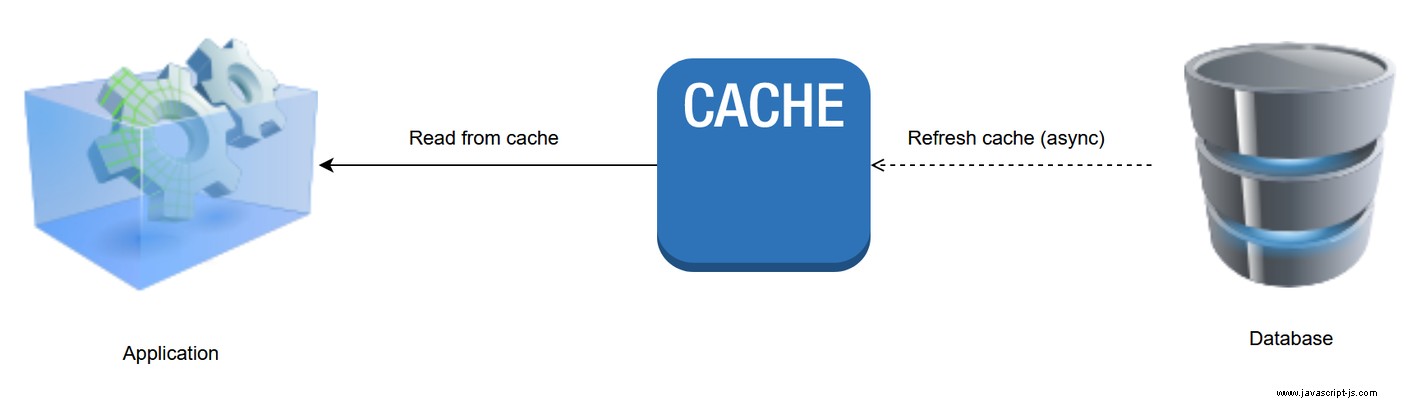
優勢
- 從數據存儲中讀取數據成本高昂時的理想選擇。
- 有助於使經常訪問的緩存條目始終保持同步。
- 非常適合對延遲敏感的工作負載,例如現場體育比賽計分網站和股市財務儀表板。
缺點
- 緩存需要準確預測未來可能需要哪些緩存項,因為不准確的預測會導致不必要的數據庫讀取。
緩存驅逐策略
與數據庫的大小相比,緩存的大小通常是有限的,因此必須只存儲需要的項目並刪除冗餘條目。緩存逐出策略通過在添加新對象時從緩存中刪除舊對象來確保緩存不超過其最大限制。有多種驅逐算法可供選擇,最好的一種將取決於您的應用程序的需求。
選擇驅逐策略時,請記住,將全局策略應用於緩存中的每個項目並不總是合適的。如果從數據存儲中檢索緩存的對象非常昂貴,則將此項保留在緩存中可能是有益的,無論是否滿足驅逐要求。可能還需要結合驅逐策略來為您的用例實現最佳解決方案。在本節中,我們將了解一些在生產環境中最流行的算法。
1。最近最少使用 (LRU)
實現 LRU 策略的緩存按使用順序組織其項目。因此,最近使用的項目將位於緩存的頂部,而最近最少使用的項目將位於底部。這樣可以很容易地確定在清理緩存時應該驅逐哪些項目。
每次訪問一個條目時,LRU 算法都會更新對像上的時間戳並將其移動到緩存的頂部。當需要從緩存中逐出某些項目時,它會分析緩存的狀態並刪除列表底部的項目。
2。最不常用 (LFU)
最不常用的算法根據訪問頻率從緩存中逐出項目。分析是通過在每次訪問緩存對象時增加一個計數器來執行的,以便在需要從緩存中逐出項目時將其與其他對象進行比較。
LFU 在緩存對象的訪問模式不經常更改的情況下大放異彩。例如,資產根據使用模式緩存在 CDN 上,因此最常用的對象永遠不會被驅逐。它還有助於驅逐在某個時間段內出現請求高峰但此後訪問頻率急劇下降的項目。
3。最近使用 (MRU)
最近使用的驅逐策略本質上與 LRU 算法相反,因為它還根據緩存項的最近訪問時間來分析緩存項。不同之處在於它會從緩存中丟棄最近使用的對象,而不是最近最少使用的對象。
MRU 的一個很好的用例是最近訪問的對像不太可能很快再次使用。例如,預訂後立即從緩存中刪除已預訂的航班座位,因為它們不再與後續預訂應用程序相關。
4。先進先出 (FIFO)
實現 FIFO 的緩存按照添加的順序逐出項目,而不考慮它們被訪問的頻率或次數。
緩存過期
緩存採用的過期策略是幫助確定緩存項目保留多長時間的另一個因素。過期策略通常在對象添加到緩存時分配給對象,並且通常針對正在緩存的對像類型進行定制。一種常見的策略是在將每個對象添加到緩存時為其分配一個絕對過期時間。一旦該時間過去,該項目將過期並相應地從緩存中刪除。這個過期時間是根據客戶需求來選擇的,例如數據變化的速度以及系統對陳舊數據的容忍度。
滑動過期策略是另一種使緩存對象無效的常用方法。此策略通過在每次訪問它們時將它們的過期時間延長指定的時間間隔來支持應用程序經常使用的保留項目。例如,一個滑動過期時間為 15 分鐘的項,只要每 15 分鐘至少訪問一次,就不會從緩存中刪除。
為緩存條目選擇 TTL 值時需要慎重。在緩存的初始實現之後,監控所選值的有效性非常重要,以便在必要時可以重新評估它們。請注意,出於性能原因,大多數緩存框架可能不會立即刪除過期項目。它們通常使用清除算法,該算法通常在引用緩存時調用,查找過期條目並刷新它們。這避免了必須不斷跟踪過期事件以確定何時應從緩存中刪除項目。
緩存解決方案
有多種方法可以在 Web 應用程序中實現緩存。通常,一旦確定需要緩存,就會為任務使用進程內緩存,因為它在概念上簡單明了,實現起來相對簡單,並且可以以最小的努力產生顯著的性能改進。進程內緩存的主要缺點是緩存對象僅限於當前進程。如果在具有多個負載平衡實例的分佈式系統中使用,您最終會得到與應用程序實例一樣多的緩存,從而導致緩存一致性問題,因為來自客戶端的請求可能會使用更新或舊數據,具體取決於所使用的服務器來處理它。如果您只緩存不可變對象,則此問題不適用。
進程內緩存的另一個缺點是它們使用與應用程序本身相同的資源和內存空間。如果在設置緩存時未仔細考慮緩存的上限,這可能會導致內存不足故障。每當重新啟動應用程序時,也會刷新進程內緩存,這會導致下游依賴項在重新填充緩存時接收更多負載。如果在您的應用程序中使用持續部署策略,這是一個重要的考慮因素。
進程內緩存的許多問題都可以通過採用分佈式緩存解決方案來解決,該解決方案提供緩存的單一視圖,即使它部署在多個節點的集群上。這意味著無論使用多少台服務器,緩存對像都在同一個地方寫入和讀取,從而減少了緩存一致性問題的發生。分佈式緩存在部署期間也會保持填充狀態,因為它獨立於應用程序本身並使用自己的存儲空間,因此您不受可用服務器內存的限制。
話雖如此,分佈式緩存的使用也帶來了自己的挑戰。它通過添加需要適當監視和擴展的新依賴項來增加系統複雜性,並且由於網絡延遲和對象序列化,它比進程內緩存慢。分佈式緩存也可能不時不可用(例如,由於維護和升級),導致性能顯著下降,尤其是在長時間停機期間。如果分佈式緩存不可用,可以通過回退到進程內緩存來緩解此問題。
進程內緩存可以在 Node.js 應用程序中通過庫實現,例如 node-cache、memory-cache、api-cache 等。有各種各樣的分佈式緩存解決方案,但最流行的是 Redis 和 Memcached。它們既是內存鍵值存儲,又是讀取繁重工作負載或計算密集型工作負載的最佳選擇,因為它們使用內存而不是傳統數據庫系統中較慢的磁盤存儲機制。
帶節點緩存的進程內緩存
下面的示例演示瞭如何在不需要復雜的設置過程的情況下執行有效的進程內緩存。這個簡單的 NodeJS 應用程序利用 node-cache 以及本文前面討論的緩存側模式,以加快從外部 API 對帖子列表的後續請求。
const express = require('express');
const fetch = require('node-fetch');
const NodeCache = require('node-cache');
// stdTTL is the default time-to-live for each cache entry
const myCache = new NodeCache({ stdTTL: 600 });
// retrieve some data from an API
async function getPosts() {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts`);
if (!response.ok) {
throw new Error(response.statusText);
}
return await response.json();
}
const app = express();
app.get('/posts', async (req, res) => {
try {
// try to get the posts from the cache
let posts = myCache.get('allPosts');
// if posts does not exist in the cache, retrieve it from the
// original source and store it in the cache
if (posts == null) {
posts = await getPosts();
// time-to-live is set to 300 seconds. After this period
// the entry for `allPosts` will be removed from the cache
// and the next request will hit the API again
myCache.set('allPosts', posts, 300);
}
res.status(200).send(posts);
} catch (err) {
console.log(err);
res.sendStatus(500);
}
});
const port = 3000;
app.listen(port, () => {
console.log(`Server listening on http://localhost:${port}`);
});
當向 /posts 發出第一個請求時 路由,緩存是空的,所以我們必須聯繫外部 API 來檢索必要的數據。當我測試初始請求的響應時間時,大約需要 1.2 秒才能收到響應。
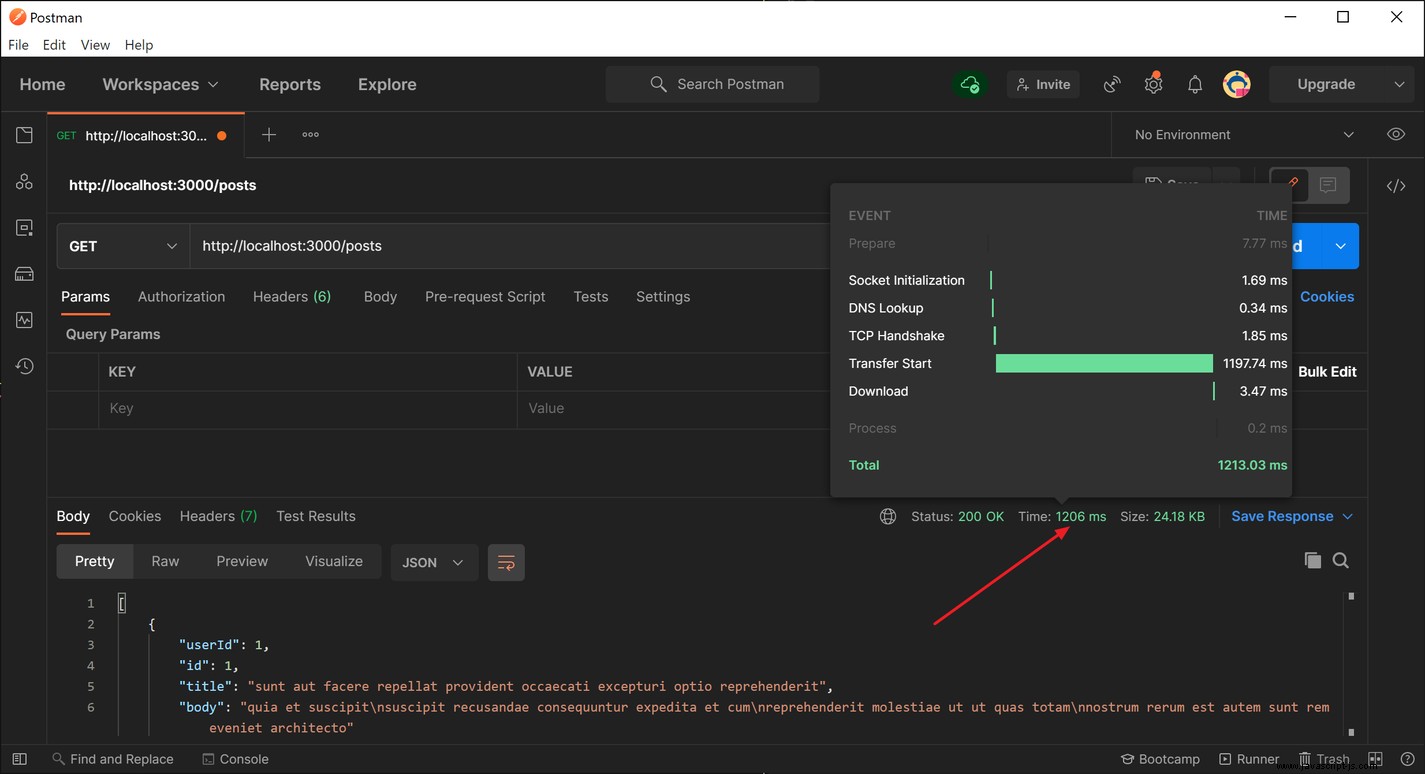
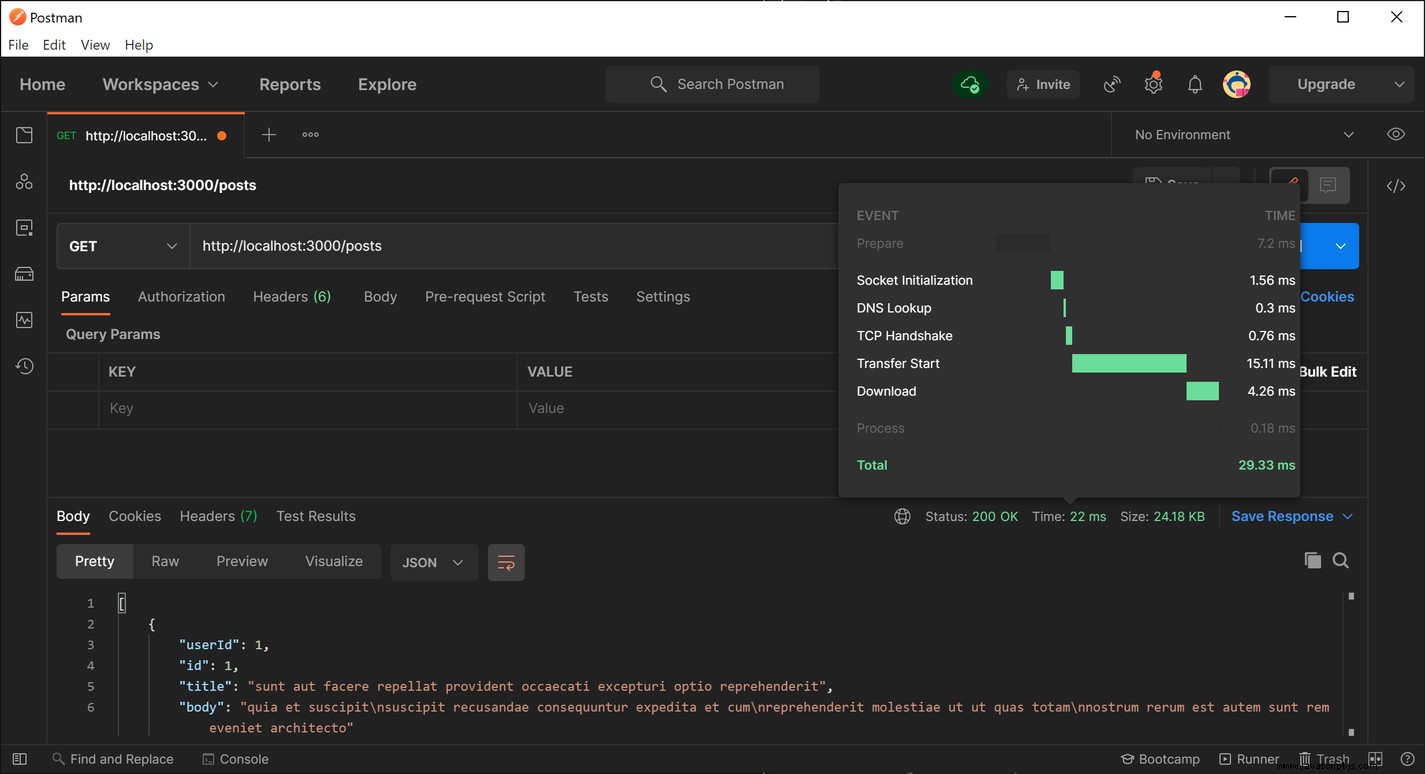
從 API 檢索數據後,將其存儲在緩存中,這會導致後續請求的解析時間大大減少。在我的測試中,我在後續請求中始終獲得大約 20-25 毫秒的響應時間,這表示與對數據發出網絡請求相比,性能提高了大約 6,000%。
使用 Redis 緩存
Redis 幾乎是適用於 Node.js 和其他語言的首選分佈式緩存解決方案。此示例展示瞭如何使用 Redis 將緩存層添加到 Node.js 應用程序。與前面使用 node-cache 的示例類似 ,要緩存的數據將從API中獲取。
在嘗試下面的示例代碼之前,請確保您已安裝 Redis。您可以按照官方快速入門指南學習如何啟動和運行它。此外,請確保在運行程序之前安裝必要的依賴項。本例使用 node-redis 庫。
const express = require('express');
const fetch = require('node-fetch');
const redis = require('redis');
const { promisify } = require('util');
const redisClient = redis.createClient();
const redisGetAsync = promisify(redisClient.get).bind(redisClient);
async function getCovid19Stats() {
const response = await fetch(`https://disease.sh/v3/covid-19/all`);
if (!response.ok) {
throw new Error(response.statusText);
}
return await response.json();
}
const app = express();
app.get('/covid', async (req, res) => {
let stats = null;
try {
// try to get the data from the cache
stats = await redisGetAsync('covidStats');
} catch (err) {
console.log(err);
}
// if data is in cache, send data to client
if (stats != null) {
res.status(200).send(JSON.parse(stats));
return;
}
try {
// otherwise, fetch data from API
stats = await getCovid19Stats();
// and store it in Redis. 3600 is the time to live in seconds
redisClient.setex('covidStats', 3600, JSON.stringify(stats));
res.status(200).send(stats);
} catch (err) {
console.log(err);
res.sendStatus(500);
}
});
const port = 3000;
app.listen(port, () => {
console.log(`Example app listening at http://localhost:${port}`);
});
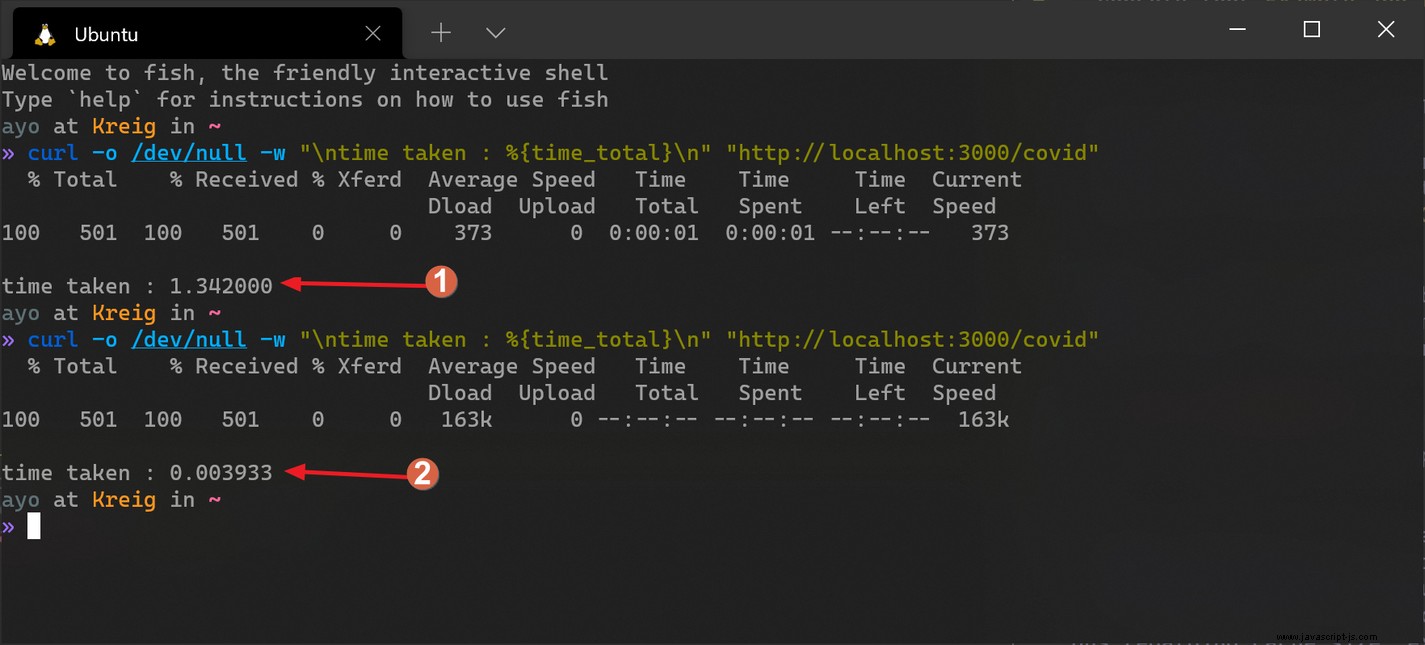
在上面的示例中,從 API 檢索全局 COVID-19 統計數據並通過 /covid 返回給客戶端 路線。這些統計信息在 Redis 中緩存 1 小時(3,600 秒),以確保將網絡請求保持在最低限度。 Redis 將所有內容都存儲為字符串,因此您必須使用 JSON.stringify() 將對象轉換為字符串 將其存儲在緩存中然後返回到具有 JSON.parse() 的對象時 從緩存中取出後,如上圖。
注意 setex 方法用於將數據存儲在緩存中,而不是常規的 set 方法。這里首選它,因為它允許我們為緩存對象設置過期時間。當設置的時間過去後,Redis 會自動從緩存中清除對象,以便再次調用 API 進行刷新。
其他注意事項
以下是在您的應用程序中實現緩存之前需要考慮的一些一般最佳實踐:
- 確保數據是可緩存的,並且會產生足夠高的命中率來證明用於緩存數據的額外資源是合理的。
- 監控緩存基礎架構的指標(例如命中率和資源消耗)以確保對其進行適當調整。使用獲得的見解來為有關緩存大小、過期和驅逐策略的後續決策提供信息。
- 確保您的系統能夠抵禦緩存故障。直接在代碼中處理緩存不可用、緩存 put/get 失敗和下游錯誤等場景。
- 如果敏感數據保留在緩存中,則利用加密技術降低安全風險。
- 確保您的應用能夠靈活應對用於緩存數據的存儲格式的變化。您的應用的新版本應該能夠讀取之前版本寫入緩存的數據。
結論
緩存是一個複雜的話題,不應掉以輕心。如果實施得當,您將獲得豐厚的回報,但如果您採用錯誤的解決方案,它很容易成為悲傷的根源。我希望這篇文章能幫助您在設置、管理和管理應用程序緩存方面朝著正確的方向前進。
感謝閱讀,祝您編碼愉快!